


Introducción
En el entorno empresarial actual, los datos son un activo valioso que puede impulsar la toma de decisiones y la innovación. Los lagos de datos permiten a las organizaciones almacenar grandes volúmenes de datos en su forma cruda, facilitando su posterior análisis. Sin embargo, la construcción de un lago de datos efectivo en la nube puede ser un proceso complejo que requiere una planificación e implementación de mejores prácticas. El Serverless Data Lake Framework (SDLF) de AWS se presenta como una solución que acelera este proceso, reduciendo el tiempo de implementación de meses a semanas.
Desarrollo
Construir un lago de datos va más allá del simple almacenamiento de archivos. Este proceso enfrenta desafíos significativos que incluyen la catalogación de datos, la creación de tuberías de ingesta, el mantenimiento de la calidad de los datos y el control de versiones del código de transformación. Cada uno de estos factores puede extender considerablemente el tiempo de implementación, desviando recursos que podrían utilizarse para la innovación y el análisis de datos.
¿Qué es un Data Lake?
Un data lake es un repositorio de almacenamiento que permite guardar datos en su forma nativa, ya sean estructurados, semiestructurados o no estructurados. A diferencia de un data warehouse, que organiza datos en tablas y requiere un esquema predefinido, un data lake permite mayor flexibilidad para almacenar y analizar grandes volúmenes de datos. Esto lo convierte en una solución ideal para empresas que buscan extraer valor de datos diversos y en constante crecimiento
¿Qué es Serverless?
La computación serverless es un modelo en el que los desarrolladores pueden construir y ejecutar aplicaciones sin preocuparse por la infraestructura subyacente. En lugar de gestionar servidores, los recursos se asignan automáticamente según la demanda, permitiendo a las empresas centrarse en el desarrollo de funciones y servicios. Este enfoque ofrece escalabilidad y una estructura de costos basada en el uso real, lo que puede resultar en ahorros significativos.
¿Por qué es útil el Serverless Data Lake Framework ?
Serverless Data Lake Framework (SDLF) proporciona una colección de artefactos reutilizables y componentes arquitectónicos diseñados para acelerar la creación e implementación de lagos de datos empresariales en la plataforma de Amazon Web Services (AWS). Su objetivo es reducir significativamente el tiempo de implementación de meses a tan solo unas pocas semanas, permitiendo que las organizaciones aprovechen rápidamente el valor de sus datos.
El SDLF facilita una base sólida sobre la cual construir un lago de datos, siguiendo las mejores prácticas establecidas en la industria. Esto incluye patrones de diseño recomendados, configuraciones de infraestructura y guías de implementación que optimizan el uso de servicios serverless y garantizan una arquitectura escalable y segura.
Arquitectura del SDLF
La arquitectura del SDLF se compone de varios componentes clave que trabajan juntos para gestionar y procesar datos en un entorno serverless. Aquí se describen los elementos principales:
Almacenamiento:
- Soluciones de almacenamiento en la nube: El corazón del SDLF es un sistema de almacenamiento en la nube, como Amazon S3, Google Cloud Storage o Azure Blob Storage. Estos servicios permiten almacenar datos de manera escalable y duradera, soportando diferentes formatos (CSV, JSON, Parquet, Delta, Hudi, Iceberg, etc).
- Estructuración de datos: Los datos pueden almacenarse en su forma cruda (capa bronce) o transformarse para facilitar su acceso (capa plata y oro). La organización de los datos es crucial para el rendimiento y la eficiencia en las consultas.
Ingesta de datos:
- Servicios de ingesta: Se utilizan herramientas como AWS Glue, Azure Data Factory o Google Cloud Dataflow para mover datos hacia el data lake. Estas herramientas permiten la ingesta de datos en tiempo real o por lotes, integrando diversas fuentes (APIs, bases de datos, IoT).
- Transformación de datos: Antes de almacenar, los datos pueden limpiarse y transformarse. Esto se puede hacer en el mismo proceso de ingesta utilizando funciones serverless.
Procesamiento de Datos:
- Computación serverless: Se emplean servicios como AWS Lambda, Azure Functions, Cloud Functions para ejecutar funciones en respuesta a eventos (por ejemplo, cuando se suben nuevos archivos de datos). Esto permite un procesamiento bajo demanda sin necesidad de aprovisionar servidores.
- Herramientas de análisis: Herramientas como Amazon Athena o Google BigQuery permiten ejecutar consultas SQL directamente sobre los datos en el data lake, proporcionando resultados rápidos sin necesidad de mover los datos.
Acceso y análisis de Datos:
- Interfaces de consulta: Proporcionan formas para que los usuarios o aplicaciones accedan a los datos. Esto puede incluir APIs RESTful o interfaces gráficas que permiten a los analistas realizar consultas y visualizar resultados.
- Integración con BI: El SDLF se puede integrar con herramientas de Business Intelligence como Tableau, Power BI o Looker para crear dashboards y reportes interactivos.
Seguridad y gobernanza:
- Controles de acceso: Implementar políticas de seguridad mediante herramientas como IAM (Identity and Access Management) para definir quién puede acceder a qué datos.
- Auditoría y monitoreo: Se utilizan servicios para rastrear el acceso a datos y cambios, garantizando la gobernanza y la conformidad regulatoria.
Orquestación:
- Flujos de trabajo: Herramientas como AWS Step Functions, Apache Airflow, Cloud Scheduler permiten orquestar flujos de trabajo complejos, coordinando la ingesta, el procesamiento y el análisis de datos de manera eficiente.
Principales características:
- Reutilización de artefactos: El SDLF incluye plantillas, scripts y configuraciones predefinidas que pueden ser reutilizadas en diferentes proyectos, lo que reduce la duplicación de esfuerzo y permite una implementación más rápida.
- Optimización del tiempo de desarrollo: Al proporcionar una estructura base y guías claras, el SDLF minimiza las barreras técnicas y permite a los equipos concentrarse en la entrega de valor en lugar de la infraestructura.
- Mejores prácticas: La arquitectura del SDLF se basa en estándares de la industria y mejores prácticas, lo que ayuda a las organizaciones a implementar soluciones que son seguras, eficientes y fáciles de mantener.
- Escalabilidad y flexibilidad: Diseñado para operar en un entorno serverless, el SDLF permite a las organizaciones escalar sus recursos automáticamente en función de la demanda, asegurando que el rendimiento se mantenga incluso a medida que crece el volumen de datos.
- Integración sencilla: El SDLF facilita la integración con otros servicios de la nube, proporcionando un ecosistema cohesivo que simplifica el flujo de trabajo de datos.
- Aceleración de la innovación: Al disminuir el tiempo de implementación, las organizaciones pueden experimentar e innovar más rápidamente, utilizando los datos para impulsar decisiones empresariales informadas y estrategias basadas en datos.
Ventajas de la Arquitectura SDLF
- Costo-efectividad: Pago por uso, donde solo se cobran los recursos consumidos, lo que reduce costos fijos.
- Facilidad de implementación: Al usar servicios en la nube, las empresas pueden implementar rápidamente soluciones de data lake sin inversiones iniciales significativas en hardware.
Caso de uso de ETL en un entorno Serverless con AWS
El proceso de ingesta y transformación de datos en un entorno serverless, el cual se encuentra ilustrado en la imagen 1, comienza con la adición de archivos al depósito de datos sin procesar en Amazon S3. Este evento genera automáticamente una notificación que se envía a una cola de Amazon SQS, la función de AWS Lambda la consume y enruta el evento al proceso ETL adecuado. A través de diversas etapas, incluyendo la actualización de metadatos y transformaciones, se asegura una gestión eficiente de los datos. Este enfoque integral se representa en los siguientes eventos:
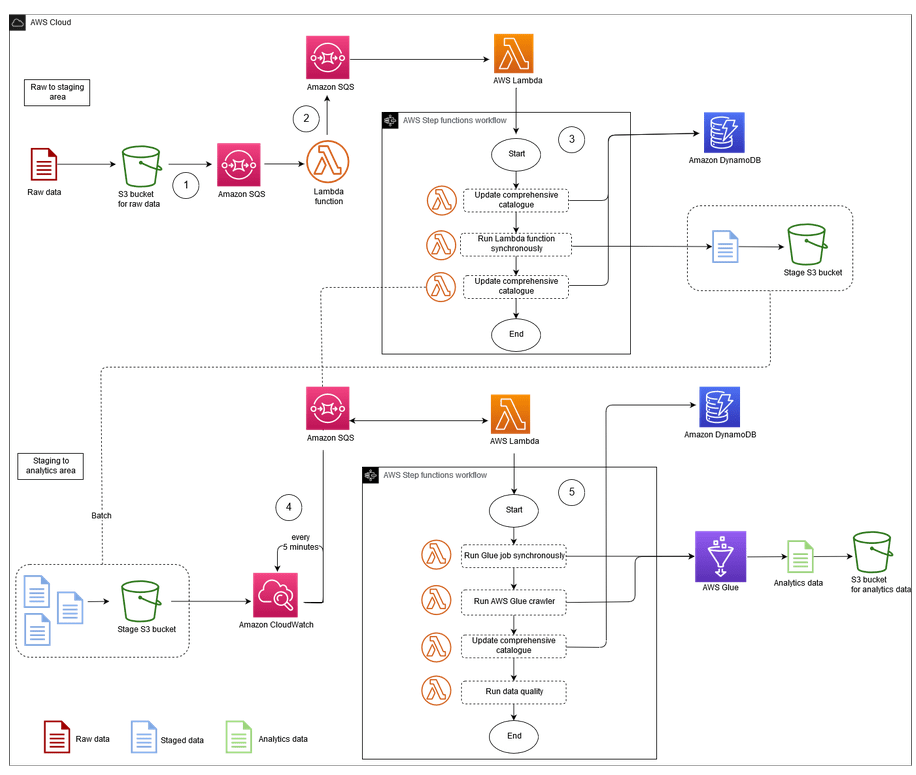
Imagen 1. Arquitectura de proceso de Ingesta y ETL en un Serverless Data Lake
Ingesta de datos en amazon S3:
Cuando se añade un archivo al depósito de datos sin procesar en Amazon S3, se genera automáticamente una notificación de evento. Esta notificación se envía a una cola de Amazon SQS (Simple Queue Service) con un archivo JSON que incluye metadatos cruciales, como:
- Nombre del bucket de S3.
- Clave del objeto (ruta del archivo).
- Marca de tiempo de la carga.
Consumo de la notificación por Lambda:
Una función de AWS Lambda se activa para consumir las notificaciones de la cola SQS. Esta función es responsable de enrutar el evento al proceso ETL adecuado, utilizando los metadatos del evento y configuraciones contextuales almacenadas en una tabla de Amazon DynamoDB. Este diseño permite desacoplar las aplicaciones y escalar eficientemente.
Proceso de extracción, transformación y carga (ETL):
La función Lambda enruta el evento a la primera función ETL, que se encarga de mover y transformar los datos del área de datos sin procesar al área de ensayo del lago de datos.
- Actualización del catálogo completo: Se actualiza una tabla de DynamoDB que actúa como un catálogo de metadatos, donde cada fila representa un objeto almacenado en S3. Esta tabla proporciona información operativa sobre los archivos.
- Transformación inicial: Se llama a otra función Lambda de forma sincrónica para realizar una transformación ligera en el objeto S3, como la conversión de un formato a otro. Esta transformación inicial es eficiente en términos de costos computacionales.
- Notificación a SQS: Tras actualizar el catálogo, se envía un mensaje a la cola SQS, preparando el sistema para la siguiente fase del proceso ETL.
Ejecución de ETL programada con CloudWatch:
Una regla de eventos de Amazon CloudWatch se establece para activar una función Lambda cada 5 minutos. Esta función comprueba si hay mensajes en la cola SQS de la fase anterior del ETL. Si se detecta un mensaje, la función Lambda inicia el siguiente paso del proceso utilizando AWS Step Functions.
Transformación profunda de datos:
- Aplicación de transformaciones complejas: En esta fase, se ejecuta una transformación profunda en un lote de archivos. Esta operación puede implicar: Llamadas a AWS Glue para trabajos de transformación, uso de AWS Fargate o Amazon EMR para procesamiento de datos en grandes volúmenes, y ejecución de cuadernos en Amazon SageMaker para análisis y modelado de datos (Machine Learning).
- Actualización del catálogo de metadatos: Un rastreador de AWS Glue se utiliza para extraer metadatos de los archivos de salida, actualizando automáticamente el catálogo de AWS Glue. Estos metadatos también se añaden a la tabla de catálogo completa en DynamoDB.
Control de Calidad de Datos:
- Ejecución de pasos de calidad: Se implementa un paso de calidad de datos utilizando Deequ, una biblioteca para validar y medir la calidad de los datos, asegurando que los datos transformados cumplan con los estándares necesarios antes de su almacenamiento final.
El proceso integral descrito para la ingesta y transformación de datos en un entorno serverless ilustra claramente los beneficios y la eficiencia que el Serverless Data Lake Framework (SDLF) puede ofrecer a las organizaciones. Al combinar la flexibilidad de los servicios serverless de AWS con una arquitectura bien definida, el SDLF permite a las empresas gestionar grandes volúmenes de datos de manera efectiva y ágil.
La automatización de la ingesta, el procesamiento ETL y el control de calidad de datos dentro del SDLF no solo acelera el tiempo de implementación, sino que también reduce la complejidad operativa. Con el uso de herramientas como AWS Lambda, SQS y AWS Glue, el SDLF facilita un flujo de trabajo desacoplado que puede escalar según las necesidades del negocio.
Conclusiones
El Serverless Data Lake Framework (SDLF) de AWS es una herramienta versátil para las organizaciones que buscan implementar lagos de datos de manera eficiente y efectiva. Su enfoque en la infraestructura como código, combinado con prácticas de CI/CD y la integración de mejores prácticas, permite a las empresas centrarse en la generación de valor a partir de sus datos en lugar de desafíos técnicos respecto a la implementación. A medida que las organizaciones continúan buscando formas de optimizar el uso de datos, SDLF se establece como una solución viable y robusta para construir lagos de datos en la nube.
Referencias
- https://aws.amazon.com/what-is/data-lake/#:~:text=A%20data%20lake%20is%20a,unstructured%20data%20at%20any%20scale
- https://aws.amazon.com/es/serverless/
- https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-a-data-lake#:~:text=risks%20more%20efficiently.-,What’s%20the%20difference%20between%20a%20data%20lake%20and%20a%20data,as%20specific%20BI%20use%20cases.
- https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-serverless-computing/
- https://sdlf.readthedocs.io/en/latest/
- https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-serverless-computing/