


Palabras clave: Data Lake – Data Warehouse – Lakehouse – Big Data – Análisis avanzado – Machine Learning
Introducción
En la era digital actual, el volumen de datos generados por las organizaciones crece a un ritmo acelerado, lo que presenta tanto oportunidades como desafíos. La arquitectura de datos es crucial para gestionar, almacenar y analizar estos datos de manera eficiente. Este artículo analiza la evolución de la arquitectura de datos y presenta soluciones clave como los Data Lakes, Data Warehouses y Lakehouses, que permiten a las organizaciones extraer valor de grandes volúmenes de datos para tomar decisiones más informadas.
Conceptos Básicos
Definición 1 (Data estructurada). Los datos estructurados son aquellos que se organizan de manera predecible y se almacenan en formatos definidos, como tablas con filas y columnas en bases de datos relacionales. Incluyen información que puede ser fácilmente ingresada, consultada, reportada y analizada, como nombres, fechas, números de teléfono y direcciones de correo electrónico. Esta estructura definida permite un acceso eficiente, facilitando operaciones como búsquedas, análisis y generación de informes.
Definición 2 (Data no estructurada). Los datos no estructurados son aquellos que no siguen un modelo o formato predefinido, lo que dificulta su almacenamiento y análisis mediante métodos convencionales. Ejemplos incluyen texto libre, imágenes, videos, correos electrónicos, publicaciones en redes sociales y otros archivos multimedia. Estos datos requieren herramientas y técnicas especializadas para su procesamiento y análisis, ya que no se ajustan a las estructuras tradicionales como tablas o bases de datos relacionales.
Definición 3 (ETL). ETL, acrónimo de Extract, Transform, Load, es un proceso que consiste en extraer datos de diferentes fuentes, aplicarles una serie de transformaciones (como limpieza o agregación), y finalmente cargarlos en un sistema de destino, como un Data Warehouse o un Data Lake. Este proceso es esencial para preparar los datos para el análisis.
Definición 4 (ACID). ACID, acrónimo de Atomicity, Consistency, Isolation, Durability, describe un conjunto de propiedades que garantizan la fiabilidad de las transacciones en sistemas de bases de datos. En español, se traduce como Atomicidad, Consistencia, Aislamiento y Durabilidad. Una transacción se considera ACID si cumple con estas propiedades, asegurando la integridad y coherencia de los datos.
Arquitecturas de datos
La arquitectura de datos ha evolucionado significativamente desde los primeros sistemas simples de archivos y bases de datos en los inicios de la informática, pasando por las bases de datos relacionales en los años 70, que mejoraron el acceso y la gestión de datos. A medida que crecieron los volúmenes de datos y se diversificaron los tipos (estructurados y no estructurados), surgieron soluciones como los Data Lakes y NoSQL para manejar grandes volúmenes de datos variados. En la actualidad, conceptos como Big Data, cloud computing y Lakehouse reflejan un enfoque hacia arquitecturas más flexibles y escalables, capaces de soportar análisis avanzados y machine learning.
La arquitectura de datos moderna debe gestionar tanto datos estructurados como no estructurados, integrando fuentes internas y externas, y ser capaz de escalar para soportar grandes volúmenes. Además, facilita el análisis avanzado y la toma de decisiones. Las tres arquitecturas principales: Data Warehouse, Data Lake y Lakehouse, surgieron para abordar diferentes necesidades: los Data Warehouses se especializan en almacenar y analizar datos estructurados de manera eficiente, los Data Lakes permiten almacenar datos variados en bruto, y los Lakehouses combinan lo mejor de ambos, ofreciendo almacenamiento escalable y capacidades de análisis avanzados.
Data Warehouse
Un Data Warehouse es un sistema de almacenamiento de datos diseñado para consolidar, almacenar y analizar grandes volúmenes de información provenientes de diversas fuentes dentro de una organización. Su principal objetivo es facilitar el acceso a datos relevantes para apoyar la toma de decisiones estratégicas. Este tipo de sistema es esencial para el análisis de datos históricos y la generación de informes, ya que permite realizar consultas eficientes y obtener información valiosa de manera rápida.
La arquitectura de un Data Warehouse incluye principalmente el proceso de extracción, transformación y carga (ETL), que consiste en extraer datos de diversas fuentes, transformarlos para asegurar su calidad y consistencia, y cargarlos en un formato optimizado para análisis y consultas. Una vez los datos están almacenados, el sistema los organiza de manera que se facilite la generación de reportes y el análisis de tendencias (figura 1). Este tipo de sistema está optimizado para manejar datos estructurados, como registros financieros o datos transaccionales, que son procesados y organizados para el análisis. Los Data Warehouses son ideales para soportar grandes volúmenes de datos y usuarios concurrentes, permitiendo un análisis histórico de la información para ayudar en la toma de decisiones empresariales.
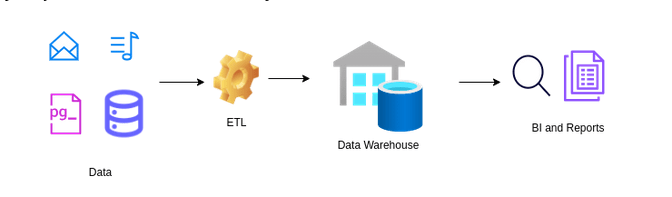
Figura 1: Arquitectura de un Data Warehouse
Un Data Warehouse no solo almacena datos estructurados, sino que también facilita la integración de datos de diversas fuentes para análisis históricos y toma de decisiones estratégicas. Además, sus capacidades modernas incluyen procesamiento analítico en línea (OLAP) e inteligencia artificial para mejorar la extracción de conocimiento y patrones. Es clave en la estrategia de inteligencia de negocios de una organización.
Data Lake
Un Data Lake es una arquitectura de almacenamiento que permite guardar grandes volúmenes de datos en su formato original, ya sean estructurados, semi-estructurados o no estructurados. Esto facilita el almacenamiento de datos en bruto, como registros, imágenes o datos de sensores, sin necesidad de estructurarlos previamente. Es particularmente útil en contextos de big data y ciencia de datos, donde se requieren grandes cantidades de información de diversas fuentes para su análisis y procesamiento posterior. Los Data Lakes son ideales para tareas de análisis avanzado y machine learning, ya que permiten realizar análisis detallados y descubrir patrones en datos complejos, como los provenientes de redes sociales o dispositivos IoT.
Además de ser un depósito para almacenar datos de múltiples fuentes, un Data Lake es un sistema flexible que permite una amplia gama de operaciones de procesamiento de datos, como la exploración, minería de datos y procesamiento de eventos en tiempo real. Su arquitectura escalable horizontalmente le permite manejar el crecimiento exponencial de los datos, integrando capacidades de gobernanza y calidad de datos para garantizar que la información almacenada sea confiable, segura y lista para el análisis.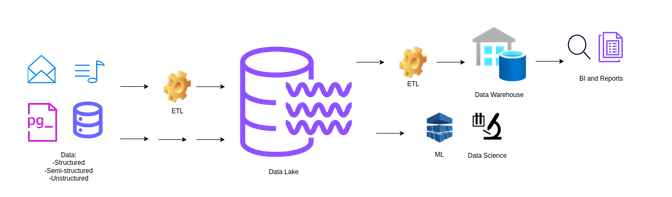
Figura 2: Arquitectura de un Data Lake
La figura 2 representa la arquitectura de un Data Lake, donde los datos de diversas fuentes (como correos electrónicos, archivos de música, bases de datos como PostgreSQL) son recopilados, Se destaca la capacidad de almacenar datos en bruto, sin procesar, en su formato original, lo que permite una mayor flexibilidad para el análisis y la generación de reportes. Estos datos son luego procesados a través de un sistema ETL (Extract, Transform, Load), y almacenados en un Data Lake. Desde aquí, pueden ser nuevamente procesados y refinados para su uso en un Data Warehouse y pueden ser utilizados directamente para tareas de ciencia de datos y machine learning (ML), lo que permite análisis avanzados y la generación de reportes de inteligencia de negocios (BI).
Lakehouse
Un Lakehouse es una plataforma de almacenamiento de datos que combina las ventajas de un Data Lake y un Data Warehouse, ofreciendo almacenamiento flexible y de bajo costo, junto con las capacidades de análisis avanzado y procesamiento estructurado típicas de los Data Warehouses. Este enfoque permite gestionar tanto datos estructurados como no estructurados, soportando transacciones consistentes y fiables, y facilitando operaciones como machine learning y análisis en tiempo real.
Una de las características clave de los Lakehouses es la integración de transacciones ACID (Atomicidad, Consistencia, Aislamiento y Durabilidad), lo que garantiza que las operaciones de escritura y procesamiento de datos sean coherentes, confiables y seguras, incluso en entornos de alta concurrencia. Al incorporar transacciones ACID, los Lakehouses aseguran que las modificaciones a los datos sean atómicas, es decir, se realicen en su totalidad o no se realicen en absoluto, manteniendo la integridad del sistema. Además, el principio de consistencia asegura que los datos almacenados sigan las reglas de negocio definidas, mientras que el aislamiento permite que las operaciones concurrentes no interfieran entre sí, evitando inconsistencias. La durabilidad, por su parte, garantiza que los datos procesados se conserven permanentemente, incluso en caso de fallos del sistema.
Además, los Lakehouses integran características clave como la gestión de metadatos, gobernanza de datos y seguridad empresarial, eliminando la necesidad de silos de datos separados y facilitando una toma de decisiones más integrada y eficiente.
Los Lakehouses representan una evolución significativa en la arquitectura de datos, fusionando la escalabilidad y flexibilidad de los Data Lakes con las potentes capacidades de procesamiento de los Data Warehouses. Al hacerlo, ofrecen una plataforma unificada que permite el análisis avanzado de datos y el aprendizaje automático, mientras mantienen la calidad y la gobernanza de los datos. Estos sistemas están diseñados para manejar datos semi-estructurados y no estructurados, como JSON, XML, videos e imágenes, y proporcionan herramientas de procesamiento avanzadas para transformar y analizar estos grandes volúmenes de datos de manera eficiente.
 Figura 3: Arquitectura de un Data Lakehouse
Figura 3: Arquitectura de un Data Lakehouse
La figura 3 muestra la arquitectura de un Data Lakehouse, que combina las características de un Data Lake y un Data Warehouse. Los datos pasan por procesos ETL para ser almacenados en el Data Lake y luego se gestionan mediante una capa adicional que incluye metadatos, caché e indexación. Esta arquitectura híbrida optimiza operaciones de data science y machine learning (ML), permitiendo análisis profundos y generación de informes de inteligencia de negocios (BI).
Las arquitecturas de datos, como Data Lakes, Data Warehouses y Lakehouses, son fundamentales para gestionar y analizar grandes volúmenes de información. Cada una ofrece ventajas y presenta limitaciones según las necesidades específicas de almacenamiento, procesamiento y análisis de datos. La tabla 1 resume las principales características de estas arquitecturas para ayudar a seleccionar la más adecuada según los objetivos organizacionales.
Tabla 1. Ventajas y desventajas de la arquitectura de datos
| Arquitectura de datos | Ventajas | Desventajas |
| Data Warehouse | Optimizado para consultas analíticas: Diseñado específicamente para consultas rápidas y análisis estructurados. | Rigidez en la estructura de los datos: Solo maneja datos estructurados, lo que limita su flexibilidad para trabajar con datos no estructurados. |
| Alta eficiencia en análisis históricos: Ideal para consolidar y analizar datos históricos y transaccionales. | Escalabilidad limitada: A medida que aumentan los volúmenes de datos, puede resultar menos eficiente y costoso. | |
| Integración de múltiples fuentes: Permite integrar datos provenientes de diversas fuentes, como sistemas operacionales y bases de datos externas. | Alto costo y complejidad en ETL: El proceso ETL puede ser complejo, especialmente cuando los datos provienen de sistemas dispares y deben ser transformados. | |
| Soporte para BI y OLAP: Soporta herramientas de inteligencia de negocios (BI) y procesamiento analítico en línea (OLAP) para generar reportes y análisis. | ||
| Data Lake | Flexibilidad en el almacenamiento: Permite almacenar datos de cualquier tipo (estructurados, semi-estructurados, no estructurados) en su formato original. | Desafíos de calidad de datos: Al almacenar datos en su forma cruda, los datos pueden ser difíciles de organizar, lo que puede complicar su procesamiento. |
| Escalabilidad horizontal: Ideal para grandes volúmenes de datos, escalando fácilmente sin afectar el rendimiento. | Desempeño en consultas: La falta de estructura puede ralentizar las consultas, especialmente cuando se busca información específica. | |
| Apto para Big Data y análisis avanzados: Perfecto para análisis de datos no estructurados, machine learning, y análisis predictivo. | Compromiso con la gobernanza y seguridad: La falta de control sobre la calidad de los datos puede generar riesgos relacionados con la seguridad y la privacidad. | |
| Capacidad de integración con herramientas avanzadas de análisis: Usado en ciencia de datos, minería de datos y procesamiento en tiempo real. | ||
| Lakehouse | Combinación de lo mejor de Data Lakes y Data Warehouses: Integra la flexibilidad de los Data Lakes con las capacidades analíticas de los Data Warehouses. | Requiere un equipo que tenga la capacidad técnica para desarrollar la solución de Lakehouse de forma efectiva debido a que involucra tecnologías modernas. |
| Análisis en tiempo real y machine learning: Ofrece soporte para procesamiento avanzado de datos, incluyendo análisis en tiempo real y machine learning. | ||
| Reducción de silos de datos: Elimina la necesidad de silos de datos al integrar datos estructurados y no estructurados en una plataforma unificada. | ||
| Escalabilidad y rendimiento: Combina la escalabilidad del Data Lake con las optimizaciones del Data Warehouse para obtener un rendimiento robusto. | ||
| El Lakehouse facilita el gobierno de datos, ya que el sistema de almacenamiento dispone los metadatos para gestionar de forma efectiva los datos que almacena. | ||
| El Lakehouse asegura la consistencia y fiabilidad de los datos al incorporar transacciones ACID, lo que garantiza que las operaciones de lectura y escritura sean atómicas, consistentes, aisladas y duraderas, incluso en entornos de alta concurrencia. |
Conclusión
La arquitectura de datos es una disciplina en constante evolución que juega un papel crucial en la transformación digital de las organizaciones. Desde los primeros sistemas de bases de datos relacionales hasta los complejos entornos de Big Data, las empresas deben adaptarse a las necesidades cambiantes de almacenamiento, procesamiento y análisis de datos. En este contexto, arquitecturas como los Data Lakes, Data Warehouses y Lakehouses ofrecen soluciones diversas, cada una con sus ventajas y limitaciones, pero todas fundamentales para permitir que las organizaciones extraigan valor de sus datos y tomen decisiones basadas en información precisa y oportuna. Sin una arquitectura de datos adecuada, las empresas corren el riesgo de perder oportunidades valiosas, por lo que es crucial diseñar, implementar y gestionar estas arquitecturas de manera estratégica para lograr un impacto positivo en el negocio.
Referencias
- Ralph Kimball, The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, 3rd Edition, John Wiley & Sons, 2013.
- Armbrust, Michael et al. The Case for Cloud Data Lakes: Modern Analytical Architectures for AI. Databricks, 2020.
- Databricks. Delta Lake: Reliable Data Lakes at Scale.