


Palabras clave: Delta Lake, Gestión de datos, Data lake, Data warehouse, Apache Spark, Transacciones ACID.
Introducción
En un mundo impulsado por los datos, las organizaciones enfrentan el desafío de gestionar grandes volúmenes de información de manera eficiente y confiable. Es aquí donde entra en escena Delta Lake, una capa de almacenamiento de código abierto creada sobre Apache Spark, un motor de procesamiento distribuido de alto rendimiento diseñado para el análisis de grandes conjuntos de datos. Apache Spark permite realizar operaciones a gran escala en memoria, lo que acelera tareas como el procesamiento de datos en tiempo real y el análisis batch.
Delta Lake combina lo mejor de los data lakes tradicionales y los data warehouses. Su objetivo principal es garantizar que los datos sean confiables, consistentes y fáciles de consultar. Esto se logra mediante funcionalidades como el manejo de transacciones ACID, el soporte para actualizaciones y eliminaciones en tiempo real, y la capacidad de versionado de datos.
En otras palabras, Delta Lake proporciona la base sólida que muchos sistemas de análisis de datos necesitan, especialmente cuando se trabaja con datos que cambian rápidamente o que provienen de múltiples fuentes.
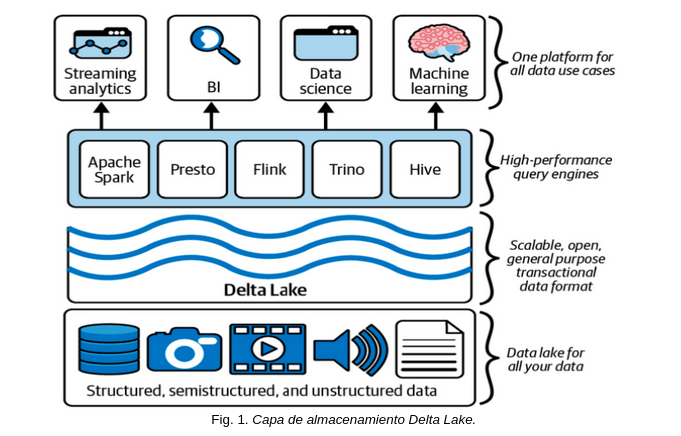
Como se muestra en la Fig.1, Delta Lake unifica y gestiona grandes volúmenes de datos de manera eficiente. Esta plataforma escalable y abierta soporta datos estructurados, semiestructurados y no estructurados. Integra motores de consulta de alto rendimiento como Apache Spark, Presto, Flink y Hive, lo que permite realizar análisis en tiempo real, business intelligence, ciencia de datos y machine learning. Además, ofrece transacciones ACID para garantizar la integridad de los datos, transformando los data lakes tradicionales en plataformas más confiables y optimizadas para diversas aplicaciones analíticas.
¿Qué problemas resuelve Delta Lake?
En el pasado, las organizaciones se enfrentaban a limitaciones importantes con los data lakes tradicionales:
- Datos inconsistentes: Los data lakes tradicionales no siempre cuentan con mecanismos adecuados para garantizar la integridad de los datos. Los errores en el procesamiento de datos o las escrituras concurrentes, es decir, cuando múltiples procesos intentaban modificar los mismos datos simultáneamente, podían generar inconsistencias y corrupción de los datos. Sin embargo, algunos data lakes avanzados implementan soluciones para abordar estos problemas, pero Delta Lake optimiza estas capacidades significativamente al añadir características como transacciones ACID.
- Actualizaciones complejas: En un data lake convencional, realizar cambios en los registros existentes, como actualizaciones o eliminaciones, resultaba ser un proceso complicado y propenso a errores. La falta de transacciones controladas dificulta la modificación de datos sin causar interrupciones en el flujo de trabajo, lo que afectaba la calidad y precisión de los datos almacenados. Delta Lake resuelve este desafío proporcionando un sistema de transacciones que garantiza la integridad durante estas operaciones.
- Difícil integración de datos en tiempo real: Los data lakes tradicionales no fueron diseñados para manejar datos que llegan de manera continua o que requieran procesamiento inmediato. Esto dificulta la integración de fuentes de datos en tiempo real, lo que limita la capacidad de las organizaciones para tomar decisiones basadas en información actualizada de manera continua. Delta Lake resuelve este problema al ser compatible con procesos de streaming en tiempo real utilizando Apache Spark, lo que permite procesar datos casi instantáneamente a medida que llegan.
Delta Lake aborda estos problemas ofreciendo:
- Transacciones ACID: Delta Lake asegura que todas las operaciones en el sistema sean atómicas, consistentes, aisladas y duraderas (propiedades ACID). Esto significa que, incluso en casos de fallos o errores, las transacciones son completadas correctamente o revertidas, lo que garantiza que los datos sean siempre consistentes y fiables, incluso en un entorno distribuido.
- Almacenamiento optimizado: Delta Lake utiliza el formato de almacenamiento Parquet junto con un sistema de registros de transacciones. Este diseño mejora tanto el rendimiento como la confiabilidad, ya que permite una lectura y escritura de datos mucho más eficiente y facilita la gestión de grandes volúmenes de datos. Además, Parquet es un formato en columnas que optimiza aún más las consultas de grandes volúmenes de datos al permitir lecturas eficientes.
- Escalabilidad: Delta Lake está diseñado para manejar grandes volúmenes de datos y realizar consultas complejas de manera eficiente. Gracias a su integración con Apache Spark y su arquitectura optimizada, Delta Lake puede escalar horizontalmente para gestionar petabytes de datos sin comprometer el rendimiento. Delta Lake también maneja los metadatos a nivel de archivo mediante un registro de transacciones separado, lo que permite optimizar aún más las consultas al ignorar archivos innecesarios.
- Integración en tiempo real: Gracias a su arquitectura, es posible manejar datos en tiempo real, permitiendo su procesamiento y actualización continua sin errores.
Delta Lake gestiona los metadatos a nivel de archivo mediante un registro de transacciones independientes (transaction log). Este enfoque permite un acceso rápido y eficiente a los metadatos, lo que facilita la toma de decisiones informadas sobre qué datos procesar y cuáles omitir. Al utilizar esta información, Delta Lake puede instruir al motor de consultas para que ignore archivos innecesarios o no relevantes, evitando lecturas innecesarias y mejorando significativamente el rendimiento de las consultas. Además, el registro de transacciones asegura que las operaciones sean consistentes y duraderas, permitiendo un seguimiento preciso de todas las modificaciones realizadas sobre los datos, lo que contribuye a la integridad del sistema y al rendimiento optimizado en entornos de grandes volúmenes de datos.
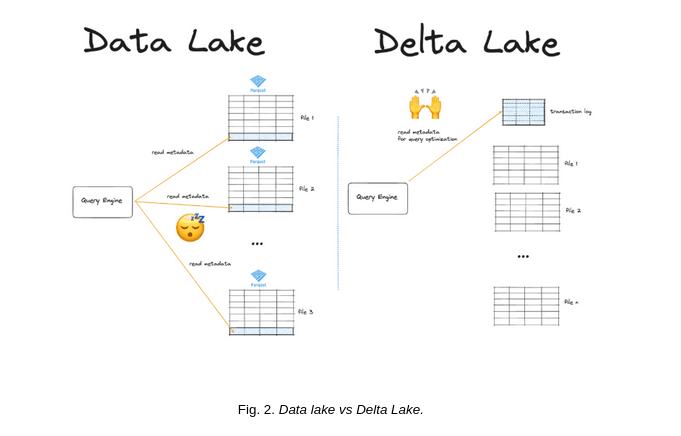
En la Fig. 2 se muestra una comparación entre un Data Lake y un Delta Lake. En el Data Lake, los motores de consulta leen directamente los metadatos de los archivos, lo que puede generar ineficiencias. En cambio, en el Delta Lake, los motores de consulta utilizan un registro de transacciones optimizado para garantizar consistencia y mayor rendimiento en las operaciones.
Ejemplo práctico: Arquitectura de Delta Lake
Un ejemplo práctico del uso de Delta Lake puede representarse mediante un diagrama de arquitectura que ilustre cómo funciona la integración de datos en tiempo real utilizando la arquitectura Medallion. La arquitectura Medallion organiza los datos en tres niveles:
Bronze (datos crudos): Ingesta de datos desde múltiples fuentes, como Kafka o archivos de registro.
Silver (datos limpios): Procesamiento y limpieza de datos con Apache Spark.
Gold (datos listos para análisis): Agregación y optimización de los datos para análisis y BI.
Flujo de procesos: A continuación, se muestra un diagrama práctico de una pipeline ETL utilizando Delta Lake y la arquitectura Medallion: 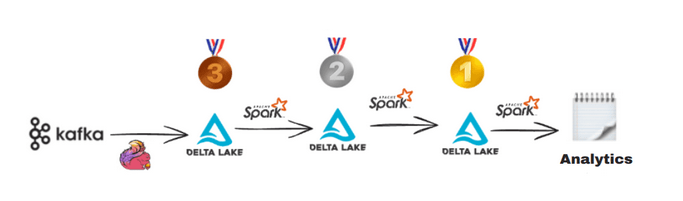 Fig. 3. Pipeline con Delta Lake.
Fig. 3. Pipeline con Delta Lake.
El diagrama de la Fig. 3 ilustra una pipeline ETL utilizando Delta Lake y la arquitectura Medallion, estructurada en tres niveles: Bronze, Silver y Gold. En el primer nivel, Bronze, los datos crudos se ingieren de manera eficiente desde diversas fuentes, como Kafka o archivos de registro, y se almacenan de forma rápida aunque aún desordenados o no estructurados. Este nivel está diseñado para capturar grandes volúmenes de datos en tiempo real sin realizar transformaciones significativas, lo que permite una ingesta rápida y escalable.
Una vez almacenados en el nivel Bronze, los datos son procesados y limpiados utilizando Apache Spark, una herramienta para el procesamiento distribuido de datos. A medida que los datos avanzan al nivel Silver, se transforman y organizan adecuadamente, eliminando errores, duplicados y valores inconsistentes. En este nivel, los datos ya están listos para análisis más detallados, aunque pueden requerir agregaciones o enriquecimientos adicionales para alcanzar la calidad necesaria para las decisiones empresariales.
En el nivel Gold, los datos se encuentran completamente transformados, optimizados y estructurados para su análisis avanzado y toma de decisiones. Este nivel incluye la consolidación de datos de múltiples fuentes, la aplicación de métricas clave y la preparación de datos para informes o modelos predictivos. Los datos en el nivel Gold son ideales para ser utilizados en procesos de inteligencia empresarial (BI), análisis de tendencias o machine learning.
Finalmente, en cada uno de estos niveles, se utilizan herramientas de Business Intelligence (BI) para visualizar, explorar y tomar decisiones basadas en los datos. Estas herramientas permiten a los usuarios interactuar con los datos de manera intuitiva, realizar consultas complejas y generar reportes o dashboards dinámicos que reflejan el estado y las tendencias clave de la organización. Este flujo organizado y estructurado de datos desde su ingesta cruda hasta su visualización final asegura que los datos sean procesados de manera eficiente, precisa y accesible para los tomadores de decisiones.
Este enfoque escalonado y estructurado asegura que los datos sean confiables, gestionables y accesibles en todas las etapas del proceso, optimizando tanto el rendimiento como la integridad de la información.
Beneficios clave de Delta Lake
Delta Lake ofrece ventajas significativas para la gestión de datos (Tabla 1), mejorando la eficiencia, fiabilidad y escalabilidad de los procesos de almacenamiento y procesamiento.
Tabla 1. Beneficios de Delta lake
Beneficio | Descripción |
Confiabilidad | Las transacciones ACID garantizan que los datos sean consistentes y confiables. |
Flexibilidad | Integración con Apache Spark y otras herramientas de Big Data. |
Escalabilidad | Manejo de grandes volúmenes de datos y procesamiento eficiente. |
Análisis rápido | Consultas optimizadas gracias al formato de almacenamiento Parquet. |
Economía | Solución de código abierto que reduce costos de licencia. |
Conclusión
Delta Lake representa un avance crucial en la evolución de la gestión de datos, abordando desafíos que históricamente limitaron a los data lakes tradicionales, como la inconsistencia de los datos y la dificultad para realizar actualizaciones en tiempo real. Al integrar características clave como transacciones ACID, almacenamiento optimizado y escalabilidad, Delta Lake no solo mejora la confiabilidad y el rendimiento de los sistemas de almacenamiento, sino que también habilita la implementación del concepto de Data Lakehouse, que combina lo mejor de los data lakes y los data warehouses.
Esta tecnología ofrece a las empresas una plataforma robusta para gestionar grandes volúmenes de datos de manera eficiente y coherente, permitiendo decisiones basadas en información precisa y actualizada al instante. La capacidad de manejar datos en tiempo real y procesar consultas complejas de manera escalable hace que Delta Lake sea esencial en un entorno empresarial que demanda rapidez y agilidad.
Ya sea que trabajes en áreas como tecnología, finanzas, logística o cualquier otro sector que dependa de grandes volúmenes de datos, implementar Delta Lake puede transformar tu enfoque hacia el análisis de datos. En un mundo cada vez más orientado al Big Data y a la toma de decisiones informadas en tiempo real, adoptar soluciones como Delta Lake no solo mejora la eficiencia operativa, sino que también posiciona a las organizaciones para ser más competitivas y adaptativas frente a los cambios rápidos en el mercado.
Bibliografía
The Linux Foundation. Delta Lake:https://delta.io
pache Software Foundation. (2023). Apache Spark Overview:https://spark.apache.org
La arquitectura de datos en la era de la información.https://quind.io/blog/analitica/la-arquitectura-de-datos-en-la-era-de-la-informacion/