


Keywords: Delta Lake, Data Management, Data Lake, Data Warehouse, Apache Spark, ACID Transactions.
Introduction
In a data-driven world, organizations face the challenge of managing large volumes of information efficiently and reliably. This is where Delta Lake comes into play, a fully open-source storage layer built on top of Apache Spark, a high-performance distributed processing engine designed for analyzing large datasets. Apache Spark enables large-scale in-memory operations, accelerating tasks such as real-time data processing and batch analytics.
Delta Lake combines the best of traditional data lakes and data warehouses. Its primary goal is to ensure data is reliable, consistent, and easy to query. This is achieved through features such as ACID transaction handling, support for real-time updates and deletions, and data versioning capabilities.
In other words, Delta Lake provides the solid foundation that many data analytics systems need, especially when working with rapidly changing data or data originating from multiple sources.
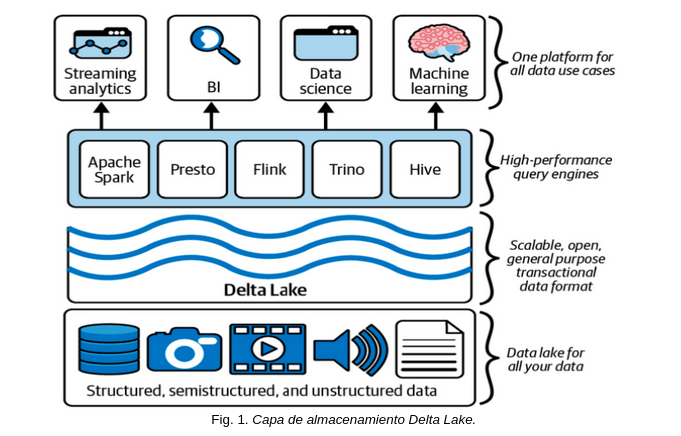
As shown in Fig. 1, Delta Lake unifies and manages large volumes of data efficiently.
This scalable and open platform supports structured, semi-structured, and unstructured data. It integrates high-performance query engines such as Apache Spark, Presto, Flink, and Hive, enabling real-time analytics, business intelligence, data science, and machine learning. Additionally, it offers ACID transactions to ensure data integrity, transforming traditional data lakes into more reliable and optimized platforms for diverse analytical applications.
What Problems Does Delta Lake Solve?
In the past, organizations faced significant limitations with traditional data lakes:
- Inconsistent Data: Traditional data lakes often lack adequate mechanisms to ensure data integrity. Errors in data processing or concurrent writes when multiple processes attempt to modify the same data simultaneously could lead to inconsistencies and data corruption. While some advanced data lakes implement solutions to address these issues, Delta Lake significantly optimizes these capabilities by incorporating features like ACID transactions.
- Complex Updates: In conventional data lakes, making changes to existing records, such as updates or deletions, was a complicated and error-prone process. The lack of controlled transactions made it difficult to modify data without disrupting workflows, affecting the quality and accuracy of stored data. Delta Lake addresses this challenge by providing a transaction system that ensures integrity during such operations.
- Difficult Real-Time Data Integration: Traditional data lakes were not designed to handle continuously arriving data or data requiring immediate processing. This made it challenging to integrate real-time data sources, limiting organizations’ ability to make decisions based on continuously updated information. Delta Lake solves this problem by supporting real-time streaming processes with Apache Spark, enabling near-instant data processing as it arrives.
How Delta Lake Addresses These Challenges
- ACID Transactions: Delta Lake ensures that all operations within the system are atomic, consistent, isolated, and durable (ACID properties). This means that even in cases of failure or errors, transactions are either completed correctly or rolled back, guaranteeing that data remains consistent and reliable, even in a distributed environment.
- Optimized Storage: Delta Lake leverages the Parquet storage format alongside a transaction log system. This design improves both performance and reliability by enabling more efficient data reading and writing while facilitating the management of large datasets. Additionally, Parquet’s columnar format further optimizes querying large datasets by allowing efficient reads.
- Scalability: Delta Lake is designed to handle vast volumes of data and execute complex queries efficiently. With its integration into Apache Spark and optimized architecture, Delta Lake can scale horizontally to manage petabytes of data without compromising performance. It manages metadata at the file level through a separate transaction log, which optimizes queries by skipping unnecessary files.
- Real-Time Integration: Thanks to its architecture, Delta Lake handles real-time data seamlessly, enabling continuous processing and updates without errors.
Delta Lake manages metadata at the file level using an independent transaction log. This approach provides fast and efficient access to metadata, enabling informed decisions about which data to process and which to omit. By utilizing this information, Delta Lake instructs the query engine to ignore unnecessary or irrelevant files, avoiding redundant reads and significantly improving query performance. Moreover, the transaction log ensures that operations are consistent and durable, allowing precise tracking of all data modifications, contributing to system integrity and optimized performance in large-scale data environments.
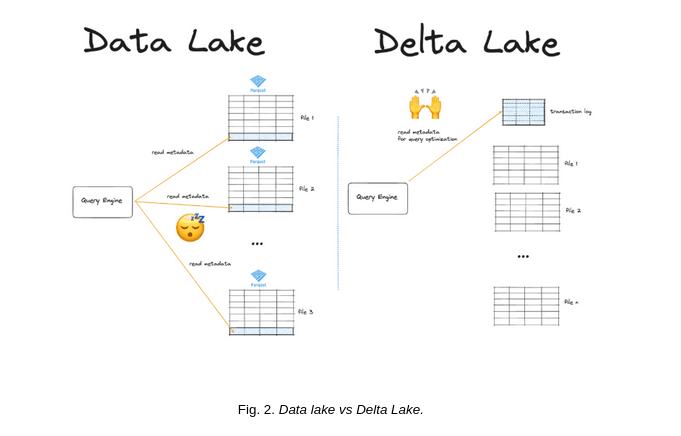
In Fig. 2, a comparison between a Data Lake and a Delta Lake is shown. In the Data Lake, query engines read file metadata directly, which can lead to inefficiencies. In contrast, in the Delta Lake, query engines use an optimized transaction log to ensure consistency and improved operational performance.
Practical Example: Delta Lake Architecture
A practical example of using Delta Lake can be represented through an architectural diagram illustrating how real-time data integration works using the Medallion architecture. The Medallion architecture organizes data into three levels:
- Bronze (raw data): Data ingestion from multiple sources, such as Kafka or log files.
- Silver (clean data): Data processing and cleaning with Apache Spark.
- Gold (analytics-ready data): Data aggregation and optimization for analysis and BI.
Process Flow: Below is a practical diagram of an ETL pipeline using Delta Lake and the Medallion architecture: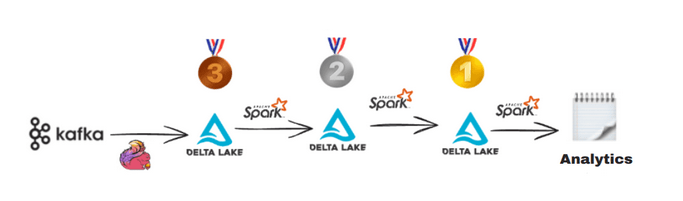
The diagram in Fig. 3 illustrates an ETL pipeline using Delta Lake and the Medallion architecture, organized into three levels: Bronze, Silver, and Gold.
At the Bronze level, raw data is efficiently ingested from various sources, such as Kafka or log files, and quickly stored, though often in an unstructured or disorganized form. This layer is designed to capture large volumes of data in real time without performing significant transformations, allowing for rapid and scalable ingestion.
Once the data is stored at the Bronze level, it is processed and cleaned using Apache Spark, a powerful tool for distributed data processing. In the Silver level, the data is transformed and organized, with errors, duplicates, and inconsistencies removed. At this stage, the data is prepared for detailed analysis, though it may still require further aggregation or enrichment to meet the quality standards necessary for business decision-making.
At the Gold level, the data is fully transformed, optimized, and structured for advanced analytics and decision-making. This stage involves consolidating data from multiple sources, applying key metrics, and preparing it for reporting or predictive modeling. The data at this level is ideal for use in business intelligence (BI) processes, trend analysis, or machine learning applications.
Throughout each level, Business Intelligence (BI) tools are utilized to visualize, explore, and enable data-driven decision-making. These tools allow users to intuitively interact with the data, perform complex queries, and generate dynamic reports or dashboards that highlight key organizational trends and states.
This structured data flow from raw ingestion to final visualization, ensures that data is processed efficiently and accurately while remaining accessible to decision-makers. This layered approach guarantees that data remains reliable, manageable, and usable at every stage, optimizing both performance and information integrity.
Key Benefits of Delta Lake
Delta Lake provides significant advantages for data management (Table 1), enhancing the efficiency, reliability, and scalability of storage and processing workflows.
Table 1. Benefits of Delta Lake
Benefit | Description |
Reliability | ACID transactions ensure that data remains consistent and reliable. |
Flexibility | Integration with Apache Spark and other Big Data tools. |
Scalability | Handles large volumes of data and ensures efficient processing. |
Fast Analysis | Optimized queries thanks to the Parquet storage format. |
Cost-Effectiveness | Open-source solution that reduces licensing costs. |
Conclusion
Delta Lake represents a crucial advancement in the evolution of data management, addressing challenges that have historically limited traditional data lakes, such as data inconsistency and difficulties with real-time updates. By integrating key features like ACID transactions, optimized storage, and scalability, Delta Lake not only enhances the reliability and performance of storage systems but also enables the implementation of the Data Lakehouse concept, which combines the best aspects of data lakes and data warehouses.
This technology provides businesses with a robust platform to manage large volumes of data efficiently and consistently, allowing for decisions based on accurate and up-to-date information. The ability to handle real-time data and process complex queries at scale makes Delta Lake essential in a business environment that demands speed and agility.
Whether you work in technology, finance, logistics, or any other sector relying on large data volumes, implementing Delta Lake can transform your approach to data analysis. In a world increasingly driven by Big Data and real-time, informed decision-making, adopting solutions like Delta Lake not only improves operational efficiency but also positions organizations to be more competitive and adaptive to rapid market changes.
References
The Linux Foundation. Delta Lake:https://delta.io
pache Software Foundation. (2023). Apache Spark Overview:https://spark.apache.org
Quind. The Data Architecture in the Information Era: .https://quind.io/blog/analitica/la-arquitectura-de-datos-en-la-era-de-la-informacion/