


La revolución DataOps: automatización y colaboración en la gestión de datos
En el mundo actual, donde la información es el principal activo empresarial, DataOps emerge como una práctica revolucionaria que transforma la manera en que las organizaciones gestionan sus datos. Inspirada en los principios de DevOps, esta metodología colaborativa busca acelerar la entrega de información, mantener estándares de calidad excepcionales y eliminar las barreras entre equipos.
DataOps se fundamenta en cinco pilares esenciales que potencian su efectividad:
- Automatización: Implementa procesos automatizados para tareas críticas como transferencia de datos e identificación de errores, liberando a los equipos para enfocarse en actividades estratégicas.
- Colaboración: Elimina los silos tradicionales entre productores y consumidores de datos, fomentando la comunicación fluida entre equipos técnicos y de negocio.
- Agilidad: Adopta principios iterativos que permiten desarrollar, probar y desplegar pipelines de datos con rapidez, adaptándose continuamente a las necesidades cambiantes.
- Calidad: Establece mecanismos de monitoreo y pruebas constantes para garantizar la precisión y confiabilidad de la información.
- Gobernanza y seguridad: Integra políticas que protegen los datos, aseguran el cumplimiento normativo y proporcionan transparencia en su uso.
En Quind hemos desarrollado una solución innovadora que se alinea perfectamente con esta filosofía DataOps, desarrollando una solución innovadora basada en el framework SDLF (Serverless Data Lake Framework) de AWS pero replicada en la infraestructura propia de Google Cloud (GCP). Esta iniciativa sienta las bases para evolucionar hacia una arquitectura DataMesh, con un propósito claro: abstraer la complejidad del aprovisionamiento de infraestructura para que los equipos de datos puedan desplegar, con mínimo esfuerzo, soluciones completas y listas para operar.
Data Mesh y SDLF: descentralización y aceleración para un manejo de datos moderno
La arquitectura Data Mesh representa un cambio paradigmático en la gestión de datos: descentraliza la propiedad y responsabilidad, delegándolas a dominios de negocio específicos. Este enfoque innovador empodera a los equipos para gestionar, procesar y analizar sus datos de forma autónoma, convirtiendo la información en productos valiosos con calidad garantizada.
Por su parte, el Serverless Data Lake Framework (SDLF) implementado sobre GCP actúa como un acelerador tecnológico, proporcionando componentes reutilizables y mejores prácticas que reducen dramáticamente la complejidad y el tiempo necesario para implementar data lakes en la nube. Su enfoque serverless maximiza la eficiencia y escalabilidad.
La simbiosis entre estos dos conceptos genera beneficios extraordinarios:
- Data Mesh establece el marco conceptual para la descentralización, mientras SDLF proporciona la base tecnológica para materializarla.
- La filosofía «Data as a Product» de Data Mesh se complementa perfectamente con las herramientas de SDLF para ingestión, transformación y gobernanza.
- La infraestructura self-service que promueve SDLF facilita que cada dominio maneje sus propios datos sin dependencias centralizadas.
- La gobernanza federada es posible gracias a los controles de seguridad y auditoría de SDLF, manteniendo estándares consistentes en un entorno descentralizado.
Esta poderosa combinación se integra naturalmente en el panorama DataOps, acelerando la transformación digital y permitiendo a las organizaciones gestionar el crecimiento exponencial de datos de manera eficiente y colaborativa.
Desafíos en la gestión tradicional de infraestructura de datos
A pesar del potencial que ofrecen DataOps, Data Mesh y SDLF, es fundamental comprender los obstáculos que han limitado históricamente la eficiencia en la gestión de datos:
El lastre del aprovisionamiento manual ha sido durante años un freno para la agilidad empresarial. Este enfoque no solo consume tiempo valioso, sino que introduce errores humanos que generan inconsistencias y retrasos. Los equipos técnicos dedican horas interminables a configurar manualmente servidores, bases de datos y canales de comunicación, en lugar de concentrarse en generar valor a partir de los datos.
La complejidad inherente al Infrastructure as Code (IaC) supone otro desafío significativo. Herramientas como Terraform con su lenguaje HCL, aunque potentes, requieren conocimientos especializados que no todos los equipos poseen. La curva de aprendizaje es pronunciada, y la integración de múltiples módulos y dependencias puede convertirse en un laberinto técnico que ralentiza proyectos críticos.
La fragmentación de esfuerzos entre equipos multiplica el problema. Sin una estrategia centralizada, cada área desarrolla soluciones aisladas, generando redundancias e incompatibilidades. El conocimiento se dispersa, las mejores prácticas no se comparten, y la organización desperdicia recursos reinventando soluciones ya existentes.
El impacto combinado de estos desafíos afecta directamente la capacidad de respuesta empresarial. El tiempo que podría dedicarse a analizar tendencias, identificar oportunidades y tomar decisiones estratégicas se consume en tareas operativas que no agregan valor directo al negocio.
Nuestra solución DataOps: simplificación a través de la abstracción y modularidad
El corazón de nuestra propuesta es un enfoque revolucionario que, basado en el framework SDLF, abstrae la complejidad del aprovisionamiento de infraestructura y sienta las bases para una arquitectura Data Mesh. Esta solución transforma radicalmente la manera en que se implementan y gestionan los data lakes.
La esencia de la solución radica en convertir procesos tradicionalmente complejos en flujos intuitivos y reproducibles. A través de plantillas YAML predefinidas, los equipos pueden desplegar soluciones completas de datos con apenas unos clics. Estas plantillas contienen toda la configuración necesaria que, procesada mediante la función yaml decode, desencadena módulos Terraform dinámicos que instancian exactamente los recursos requeridos para cada caso específico.
Esta abstracción genera beneficios transformadores:
- Liberación de recursos técnicos: Los ingenieros de datos pueden olvidarse de las complejidades del aprovisionamiento y concentrarse en perfeccionar los algoritmos y procesos que realmente generan valor.
- Enfoque en la innovación: Al eliminar las barreras técnicas, los equipos dedican su energía a mejorar la lógica de transformación y enriquecimiento de datos, optimizando la calidad y relevancia de la información procesada.
- Escalabilidad y replicabilidad: La modularidad inherente a nuestro enfoque permite reutilizar configuraciones validadas en múltiples proyectos, garantizando consistencia y acelerando implementaciones futuras.
La modularidad es particularmente poderosa: cada componente está diseñado para integrarse perfectamente con otros, creando un ecosistema flexible donde las soluciones pueden adaptarse a necesidades específicas sin sacrificar la consistencia global. Los equipos pueden personalizar aspectos específicos de sus pipelines ETL mediante scripts de Python y Bash, manteniendo una estructura estandarizada que facilita el mantenimiento y la evolución.
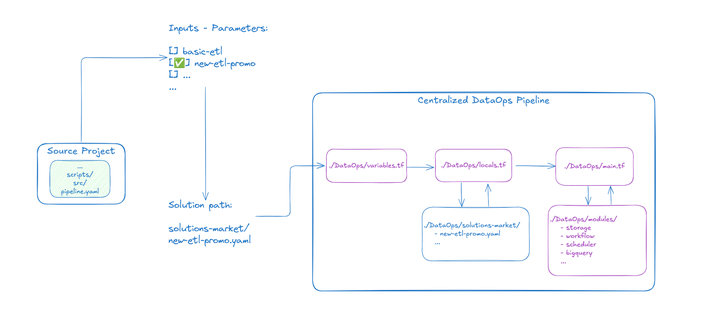
Implementación práctica: el poder de Azure DevOps Pipelines
La materialización de nuestra solución se realiza a través de Azure DevOps Pipelines, una plataforma que orquesta el despliegue automatizado de infraestructuras de datos con precisión y eficiencia. El proceso se ha diseñado para ser notablemente simple desde la perspectiva del usuario: mediante un único parámetro, se selecciona la plantilla deseada, iniciando automáticamente el despliegue de la solución completa.
El flujo técnico detrás de este proceso aparentemente sencillo es sofisticado pero elegante:
- Selección intuitiva: El usuario elige la plantilla YAML que define la infraestructura completa mediante una interfaz clara y amigable.
- Decodificación inteligente: La función yamldecode transforma el contenido YAML en estructuras de datos procesables, interpretando dinámicamente la configuración.
- Inyección dinámica: El contenido decodificado se mapea a módulos Terraform (HCL), donde se crean bloques configurados según los requisitos específicos de cada solución.
- Integración de scripts: Los scripts de Python para la lógica ETL y los scripts de Bash para el empaquetado y distribución se gestionan centralmente, garantizando su correcta integración en el pipeline final.
Esta arquitectura genera múltiples ventajas:
- Velocidad sin precedentes: Los despliegues que tradicionalmente tomaban días o semanas se completan en horas o incluso minutos.
- Visibilidad completa: Cada paso del proceso es rastreable, facilitando la identificación de problemas y la implementación de mejoras continuas.
- Consistencia garantizada: La parametrización y modularidad aseguran que cada despliegue sea idéntico, eliminando las variaciones que típicamente causan errores en entornos de producción.
El pipeline se convierte así en un habilitador estratégico, transformando la implementación de soluciones de datos en un proceso predecible y confiable que impulsa la innovación y agilidad empresarial.
Impacto real: beneficios obtenidos y lecciones aprendidas
La implementación de nuestra solución DataOps ha generado impactos significativos, proporcionando valiosas enseñanzas que guían nuestra evolución continua.
Entre los beneficios más destacables encontramos:
- Eficiencia operativa transformadora: La automatización ha reducido drásticamente los tiempos de implementación, acelerando la entrega de valor al negocio y optimizando la asignación de recursos.
- Colaboración sin precedentes: La integración de equipos multidisciplinarios ha eliminado silos tradicionales, fomentando un entorno donde el conocimiento fluye libremente entre áreas técnicas y de negocio.
- Aprovechamiento del conocimiento colectivo: La capacidad de reutilizar soluciones y aprendizajes previos ha impulsado la innovación, evitando la duplicación de esfuerzos y acelerando la madurez tecnológica.
- Escalabilidad inmediata: Las soluciones implementadas se adaptan naturalmente al crecimiento del negocio, permitiendo escalar operaciones sin un aumento proporcional en complejidad o costos.
Durante este recorrido, hemos recopilado lecciones invaluables:
- Gobernanza como pilar fundamental: Establecer políticas claras que equilibren flexibilidad y control es esencial para mantener la integridad y seguridad de los datos en un entorno descentralizado.
- El reto de definir dominios: La identificación adecuada de los límites entre dominios de datos requiere una comprensión profunda del negocio y una comunicación efectiva entre stakeholders.
- Capacitación como inversión estratégica: El desarrollo continuo de habilidades técnicas y metodológicas es indispensable para maximizar el potencial de las herramientas y enfoques implementados.
- Transformación cultural como requisito: Más allá de la tecnología, el éxito de DataOps depende de promover valores como la colaboración, transparencia y responsabilidad compartida.
El camino hacia el futuro: conclusiones y horizontes
El recorrido que hemos presentado ilustra cómo la convergencia de DataOps, Data Mesh y SDLF está transformando fundamentalmente la manera en que las organizaciones aprovechan sus datos. Esta evolución no es meramente tecnológica—representa un cambio de paradigma en cómo concebimos, implementamos y gestionamos soluciones de datos.
Nuestra solución democratiza el acceso a infraestructuras avanzadas, permitiendo que equipos con diversos niveles de experiencia técnica puedan desplegar y gestionar entornos complejos de datos. Al abstraer las complejidades subyacentes y promover la modularidad, hemos creado un ecosistema donde la innovación puede florecer sin las limitaciones tradicionales.
Lo que hemos explorado es solo el comienzo. Las posibilidades que se abren ante nosotros son vastas y emocionantes, como la evolución hacia arquitecturas completamente descentralizadas que maximicen la autonomía de los dominios de negocio.
La transformación digital de la gestión de datos no es solo una tendencia tecnológica—es una necesidad estratégica para empresas que aspiran a mantenerse competitivas en un entorno cada vez más impulsado por datos.
El futuro pertenece a quienes puedan no solo recopilar y almacenar datos, sino transformarlos en conocimientos accionables con agilidad y precisión. La combinación de DataOps, Data Mesh y herramientas como SDLF proporciona el marco para lograr exactamente eso. El camino por recorrer es apasionante, y apenas estamos vislumbrando su potencial transformador.