


Palabras clave: Kafka Streams • Spring Cloud Stream • Apache Kafka • Microservicios • Arquitectura orientada a eventos • Stream Processing • Spring Boot • Testing
Introducción
En sistemas distribuidos modernos, el procesamiento de flujos de datos en tiempo real (stream processing) se ha convertido en un componente clave para generar valor inmediato a partir de eventos: desde detección de fraudes y recomendaciones personalizadas, hasta monitoreo operativo y análisis financiero en tiempo real.
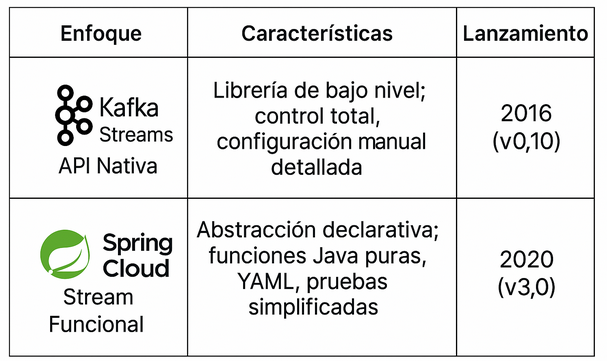
Apache Kafka, originalmente diseñado como una plataforma de mensajería distribuida, ha evolucionado hasta convertirse en un ecosistema completo para construir aplicaciones event-driven altamente escalables y tolerantes a fallos. En este contexto, Kafka Streams y Spring Cloud Stream emergen como dos enfoques distintos para procesar eventos dentro del stack de Java y Spring Boot:
- Kafka Streams: una librería ligera, poderosa y embebible que permite construir pipelines de datos directamente sobre Kafka.
- Spring Cloud Stream: una abstracción declarativa centrada en funciones Java puras, que desacopla la lógica de negocio de los detalles del transporte, permitiendo escribir microservicios con mínima configuración.
¿Qué es Kafka Streams?
Kafka Streams es una librería cliente de Java para construir aplicaciones y microservicios que consumen, procesan y producen datos en Kafka. Permite realizar transformaciones complejas como joins, agregaciones y ventanas de tiempo, sin necesidad de infraestructura externa como Apache Storm o Apache Flink.Ventajas
- Alta eficiencia y baja latencia para procesamiento en tiempo real
- DSL poderosa para operaciones complejas (joins, windowing, aggregations)
- Manejo de estado embebido con RocksDB para persistencia local
- Garantías exactly-once para procesamiento crítico
- Control total sobre la topología de procesamiento
- Escalabilidad horizontal automática basada en particiones
Limitaciones
- Configuración manual extensa y propensa a errores
- Curva de aprendizaje pronunciada para conceptos avanzados
- Testing técnico y verboso con TopologyTestDriver
- Acoplamiento directo al broker Kafka
- Complejidad de debugging en topologías complejas
¿Qué es Spring Cloud Stream?
Spring Cloud Stream es un framework que facilita la creación de aplicaciones event-driven desacopladas, mediante un modelo basado en funciones (Function, Consumer, Supplier). Abstrae la conexión con brokers como Kafka, RabbitMQ o Amazon Kinesis a través de propiedades declarativas.Ventajas
- Configuración ligera basada exclusivamente en YAML
- Desacoplamiento total entre lógica de negocio y transporte
- Portabilidad entre brokers sin modificar el código fuente
- Integración nativa con el ecosistema Spring (Boot, Security, Actuator)
- Testing simplificado con TestBinder para pruebas unitarias
- Productividad elevada y curva de aprendizaje reducida
- Observabilidad integrada con métricas y health checks
Limitaciones
- Menor control granular sobre aspectos avanzados de Kafka
- Abstracción que puede limitar optimizaciones específicas
- Dependencia del ecosistema Spring para funcionalidades completas
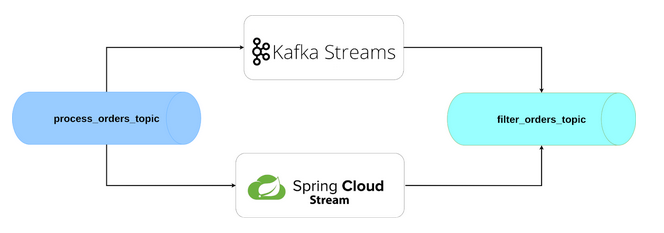
Caso de Uso: Filtrado de Órdenes por Monto
Nuestro microservicio debe implementar la siguiente lógica de negocio:- Consumir órdenes desde el topic process_orders_topic
- Validar los campos clave de cada orden (ID, customerId, amount)
- Filtrar órdenes con monto superior a $100.000 COP
- Normalizar la moneda a formato estándar
- Calcular el IVA (19%) y almacenar el total con impuesto
- Publicar las órdenes válidas y enriquecidas en filter_orders_topic
Infraestructura: Configuración Docker
Antes de implementar nuestros microservicios, configuramos el entorno Kafka usando Docker Compose:
version: ‘3.8’
services:
zookeeper:
image: docker.io/bitnami/zookeeper:3.8
restart: always
ports:
– «2181:2181»
environment:
– ALLOW_ANONYMOUS_LOGIN=yes
volumes:
– zookeeper-volume:/bitnami
kafka:
image: docker.io/bitnami/kafka:3.3
restart: always
ports:
– «9093:9093»
environment:
– KAFKA_BROKER_ID=1
– KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
– ALLOW_PLAINTEXT_LISTENER=yes
– KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CLIENT:PLAINTEXT,EXTERNAL:PLAINTEXT
– KAFKA_CFG_LISTENERS=CLIENT://:9092,EXTERNAL://:9093
– KAFKA_CFG_ADVERTISED_LISTENERS=CLIENT://kafka:9092,EXTERNAL://localhost:9093
– KAFKA_CFG_INTER_BROKER_LISTENER_NAME=CLIENT
depends_on:
– zookeeper
volumes:
– kafka-volume:/bitnami
redpanda-console:
image: docker.redpanda.com/redpandadata/console:latest
restart: always
ports:
– «8080:8080»
environment:
– KAFKA_BROKERS=kafka:9092
depends_on:
– kafka
volumes:
zookeeper-volume:
kafka-volume:
Esta configuración proporciona un cluster Kafka completo con Redpanda Console para monitoreo y administración en http://localhost:8080.
Ejemplo con Kafka Streams Tradicional
pom.xml
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.13.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.38</version>
</dependency>
Modelo de datos:
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class Order {
private String id;
private BigDecimal amount;
private String customerId;
private String currency;
private BigDecimal amountWithTax;
}
application.yml
spring:
application:
name: order-filter-app
kafka:
bootstrap-servers: localhost:9093
properties:
application.id: order-filter-app
Configuración kafka
@Configuration
@EnableKafkaStreams
public class KafkaConfig {
@Value(«${spring.kafka.bootstrap-servers}»)
private String brokers;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration kafkaStreamsConfiguration() {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, «order-filter-app»);
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, org.apache.kafka.common.serialization.Serdes.StringSerde.class);
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, org.apache.kafka.common.serialization.Serdes.StringSerde.class);
return new KafkaStreamsConfiguration(props);
}
}
Lógica de Procesamiento
@Slf4j
@Component
public class OrderFilterProcessor {
private static final BigDecimal MIN_AMOUNT = BigDecimal.valueOf(100_000);
private static final BigDecimal TAX_RATE = BigDecimal.valueOf(0.19);
private static final String DEFAULT_CURRENCY = «COP»;
private final Gson gson = new Gson();
/**
* Procesamiento tradicional usando la API de Kafka Streams.
* Lee mensajes del topic «process_orders_topic», valida y enriquece las ordenes,
* y luego escribe al topic «filter_orders_topic».
*/
@Bean
public KStream<String, String> orderFilter(StreamsBuilder builder) {
KStream<String, String> stream = builder.stream(«process_orders_topic», Consumed.with(Serdes.String(), Serdes.String()))
.flatMapValues(value -> {
try {
Order order = gson.fromJson(value, Order.class);
if (!isValid(order)) return Collections.emptyList();
if (!isHighValue(order)) return Collections.emptyList();
normalizeCurrency(order);
calculateTax(order);
log.info(«Orden procesada: {}», order.toString());
return Collections.singletonList(gson.toJson(order));
} catch (Exception e) {
log.error(«Error al deserializar orden: {}», value, e);
return Collections.emptyList();
}
})
.peek((k, v) -> log.info(«Orden lista para publicar: {}», v));
stream.to(«filter_orders_topic»);
return stream;
}
private boolean isValid(Order order) {
if (order == null) {
log.warn(«Orden nula recibida»);
return false;
}
if (order.getId() == null || order.getId().isBlank()) {
log.warn(«Orden sin ID»);
return false;
}
if (order.getCustomerId() == null || order.getCustomerId().isBlank()) {
log.warn(«Orden {} sin customerId», order.getId());
return false;
}
if (order.getAmount() == null) {
log.warn(«Orden {} sin amount», order.getId());
return false;
}
return true;
}
private boolean isHighValue(Order order) {
boolean isValid = order.getAmount().compareTo(MIN_AMOUNT) > 0;
if (!isValid) {
log.warn(«Orden {} con monto insuficiente: {}», order.getId(), order.getAmount());
}
return isValid;
}
private void normalizeCurrency(Order order) {
String currency = order.getCurrency() != null ? order.getCurrency().toUpperCase() : DEFAULT_CURRENCY;
order.setCurrency(currency);
}
private void calculateTax(Order order) {
BigDecimal tax = order.getAmount().multiply(TAX_RATE);
order.setAmountWithTax(order.getAmount().add(tax));
}
}
Spring Cloud Stream Funcional
pom.xml
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
Modelo de datos
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class Order {
private String id;
private BigDecimal amount;
private String customerId;
private String currency;
private BigDecimal amountWithTax;
}
application.yml
spring:
application:
name: order-filter-cloud
cloud:
function:
definition: processOrders # Nombre de la función principal que procesa el flujo Kafka Streams
stream:
bindings:
processOrders-in-0: # Canal de entrada para la función ‘processOrders’
destination: process_orders_topic # Topic de Kafka desde donde se consumen las órdenes
group: order-filter-group # Grupo de consumidor Kafka (coordina múltiples instancias)
processOrders-out-0: # Canal de salida para la función ‘processOrders’
destination: filter_orders_topic # Topic de Kafka donde se publican las órdenes filtradas
kafka:
streams:
binder:
brokers: localhost:9093 # Dirección del broker de Kafka
autoCreateTopics: true # Crea automáticamente los topics si no existen
Lógica funcional
@Slf4j
@Configuration
@RequiredArgsConstructor
public class OrderFilterProcessor {
// Constantes de negocio
private static final BigDecimal MIN_AMOUNT = BigDecimal.valueOf(100_000); // Monto mínimo para considerar una orden válida
private static final BigDecimal TAX_RATE = BigDecimal.valueOf(0.19); // IVA del 19%
private static final String DEFAULT_CURRENCY = «COP»; // Moneda por defecto si no se especifica
/**
* Bean que define una función de procesamiento de flujo con Kafka Streams.
* Recibe un stream de órdenes y devuelve otro con las órdenes válidas y enriquecidas.
*
* Esta función es enlazada automáticamente por Spring Cloud Stream usando el nombre del método,
* y asociada al binding configurado en application.yml (por ejemplo, processOrders-in-0).
*/
@Bean
public Function<KStream<String, Order>, KStream<String, Order>> processOrders() {
return input -> input
// Paso 1: Validar que cada orden tenga datos mínimos (ID, customerId, amount, etc.)
.filter(this::validateOrder)
// Paso 2: Filtrar solo las órdenes con monto superior al mínimo requerido
.filter(this::isHighValueOrder)
// Paso 3: Normalizar el valor de la moneda a mayúsculas o asignar COP por defecto
.mapValues(this::normalizeCurrency)
// Paso 4: Calcular el IVA (19%) y enriquecer la orden con el total con impuesto
.mapValues(this::calculateTax);
}
/**
* Valida que una orden no sea nula y contenga los campos básicos requeridos.
* Si alguna condición falla, se descarta la orden y se deja log de advertencia.
*/
private boolean validateOrder(String key, Order order) {
if (order == null) {
log.warn(«Orden nula recibida»);
return false;
}
if (order.getId() == null || order.getId().isBlank()) {
log.warn(«Orden sin ID»);
return false;
}
if (order.getCustomerId() == null || order.getCustomerId().isBlank()) {
log.warn(«Orden {} sin customerId», order.getId());
return false;
}
if (order.getAmount() == null) {
log.warn(«Orden {} sin amount», order.getId());
return false;
}
return true;
}
/**
* Evalúa si el monto de la orden supera el mínimo requerido.
* Se descartan órdenes por debajo del umbral.
*/
private boolean isHighValueOrder(String key, Order order) {
boolean isValid = order.getAmount().compareTo(MIN_AMOUNT) > 0;
if (!isValid) {
log.warn(«Orden {} con monto insuficiente: {}», order.getId(), order.getAmount());
}
return isValid;
}
/**
* Normaliza la moneda de la orden a mayúsculas. Si no se especifica, se asigna «COP».
*/
private Order normalizeCurrency(Order order) {
String currency = Optional.ofNullable(order.getCurrency())
.map(String::toUpperCase)
.orElse(DEFAULT_CURRENCY);
order.setCurrency(currency);
return order;
}
/**
* Calcula el impuesto (IVA) sobre el monto de la orden y lo agrega como nuevo campo.
*/
private Order calculateTax(Order order) {
BigDecimal tax = order.getAmount().multiply(TAX_RATE);
order.setAmountWithTax(order.getAmount().add(tax));
log.info(«Orden procesada: {}», order);
return order;
}
}
Este artículo compara ambos estilos mediante un ejemplo práctico —filtrar órdenes con valor superior a $100.000 COP y resalta las diferencias clave en términos de desarrollo, mantenimiento, portabilidad y productividad.
Comparación: Kafka Streams vs Spring Cloud Stream
| Criterio | Kafka Streams | Spring Cloud Stream |
|---|---|---|
| Configuración | Java explícito + propiedades (serdes, topologías, stores); requiere código detallado (Apache Kafka Streams Docs) | Declarativo vía application.yml; bindings preconfigurados y auto-wiring (Spring Cloud Stream Docs) |
| Testing | TopologyTestDriver para pruebas unitarias rápidas sin broker externo permite simular diferentes escenarios de tiempo (Confluent Testing Guide) | TestBinder simplifica pruebas desacopladas del broker real, integración con Spring Test |
| Portabilidad | Acoplado a Kafka: diseñado exclusivamente para Kafka | Agnóstico al broker: soporta Kafka, RabbitMQ, Redis, etc. mediante binders modulares (Spring Cloud Stream Architecture) |
| Curva de aprendizaje | Alta: requiere entender conceptos como KStream, KTable, Topology, State Store, Processor API (Kafka Streams Developer Guide) | Moderada: aunque sigue paradigmas Spring Boot, requiere entender bindings, binders y modelo funcional (Spring Cloud Stream Programming Model) |
| Control granular | Total: acceso completo al DSL y Processor API, personalización avanzada (Kafka Streams DSL) | Limitado: control a través de bindings y configuración, menos acceso directo al procesamiento (Spring Cloud Stream Functional Model) |
| Productividad inicial | Baja: requiere configuración manual detallada y mayor tiempo de setup inicial | Alta: configuración rápida, integración automática con Spring Boot (Spring Boot Auto-configuration) |
| Debugging | Complejo: requiere inspección de la topología, uso de logs detallados, JMX y herramientas externas (Kafka Streams Monitoring) | Más directo: trazas claras gracias al stack Spring, logs amigables, integración con Actuator (Spring Boot Actuator) |
| Observabilidad | Métricas por JMX nativas, requiere configuración adicional para integración con sistemas de monitoreo (Kafka Streams Metrics) | Integración nativa con Spring Actuator, métricas expuestas automáticamente via endpoints (Spring Cloud Stream Metrics) |
| Mantenimiento | Alto: más líneas de código boilerplate, configuración manual de serializadores y topologías complejas | Bajo: basado en convenciones Spring Boot y auto-configuración (Spring Boot Convention over Configuration) |
| Rendimiento | Excelente: procesamiento nativo sin capas de abstracción adicionales (Kafka Streams Performance) | Bueno: overhead mínimo por abstracción de Spring Cloud Stream, rendimiento adecuado para la mayoría de casos de uso (Spring Cloud Stream Performance Considerations) |
| Flexibilidad | Máxima: soporte completo del DSL, joins complejos, ventanas de tiempo, state stores, repartición, etc. (Kafka Streams Operations) | Limitada: funcionalidad básica de stream processing, sujeta a las capacidades del binder específico (Spring Cloud Stream Kafka Streams Binder) |
| Ecosistema | Kafka nativo: integración directa con Confluent Platform, ksqlDB, Schema Registry (Confluent Platform) | Spring Boot: integración completa con ecosistema Spring (Security, Actuator, Cloud Config, etc.) (Spring Cloud Stream Integration) |
Adopción Empresarial
Empresas que utilizan tecnologías de Stream Processing con Kafka:
Wise: Ejecuta alrededor de 300 aplicaciones de procesamiento de streams con estado utilizando Kafka Streams, gestionando más de 50 terabytes de estado en producción. Esta tecnología es una pieza clave en el movimiento de dinero dentro de su plataforma financiera global, por lo que su alta disponibilidad resulta esencial para el negocio.
Uber: Utilizan tecnologías basadas en Kafka para procesamiento de eventos de alta frecuencia en sus servicios de movilidad y logística
Confluent: Ofrece soluciones empresariales de streaming basadas en Kafka, con casos de uso documentados en múltiples industrias
Link:
Empresas del ecosistema Spring:
Las organizaciones que adoptan arquitecturas de microservicios con Spring Boot frecuentemente implementan soluciones de event streaming para comunicación asíncrona entre servicios, aunque los detalles específicos de implementación raramente se publican por razones de confidencialidad empresarial.
Nota: La elección entre diferentes tecnologías de stream processing depende de factores como la arquitectura existente, requisitos de rendimiento, y experiencia del equipo de desarrollo.
Versión de Java usada
Este proyecto fue implementado usando Java 21, lo que garantiza compatibilidad con las últimas versiones de Spring Boot y soporte para mejoras de rendimiento, eficiencia y nuevas características del lenguaje.
Conclusión
Spring Cloud Stream, especialmente con el binder de Kafka Streams, ofrece lo mejor de ambos mundos: la robustez y potencia de Kafka Streams, y la simplicidad, productividad y cohesión del ecosistema Spring Boot.
Gracias a su modelo funcional y configuración declarativa, permite a los equipos centrarse en la lógica de negocio, reducir el boilerplate y mantener el código más limpio, sin perder la capacidad de implementar flujos complejos.
En cambio, usar Kafka Streams de forma nativa es ideal sólo cuando se requiere control total sobre la topología, el estado local o características avanzadas que justifican asumir mayor complejidad técnica.
Recomendación
Elige Spring Cloud Stream si:
Quieres aprovechar la potencia de Kafka Streams con una curva de aprendizaje más baja.
Necesitas desarrollar microservicios event-driven rápidamente y con menos código.
Buscas portabilidad entre brokers (Kafka, RabbitMQ, Pulsar) sin modificar el código fuente.
Te interesa facilitar pruebas unitarias, despliegues en Kubernetes, y buenas prácticas modernas.
Usa Kafka Streams directamente solo si:
Necesitas optimizar al máximo el rendimiento o el uso de APIs avanzadas como Processor API, punctuate() o control manual del estado local.
Tienes casos con topologías altamente personalizadas o segmentaciones no estándar.
Estás fuera del ecosistema Spring y prefieres una librería standalone sin dependencias adicionales.
Importante: Spring Cloud Stream no sustituye a Kafka Streams, sino que lo extiende y abstrae, permitiendo usar sus capacidades con mayor facilidad y consistencia en entornos modernos.
Recomendación estratégica: adopta Spring Cloud Stream como primera opción. Usa Kafka Streams nativo sólo cuando una necesidad técnica específica lo justifique.
Referencias
Documentación Oficial:
Guías y Tutoriales:
Artículos de Ingeniería:
Especificaciones Técnicas: