


Introducción
En la era del big data y la inteligencia artificial, las organizaciones no solo generan más información que nunca, sino que deben procesarla y analizarla a velocidades cada vez mayores para mantener su competitividad. El problema es que muchas arquitecturas de datos tradicionales no están diseñadas para manejar simultáneamente grandes volúmenes, variedad de formatos y cargas de trabajo que requieren análisis en tiempo real. Esto se traduce en procesos ETL lentos, silos de información y altos costos operativos.
Aquí es donde Databricks se ha convertido en un actor clave: su arquitectura Lakehouse permite unificar almacenamiento y análisis, integrando la potencia de Apache Spark con herramientas de gobernanza, machine learning y procesamiento distribuido en un solo entorno. Esto ayuda a resolver retos como la fragmentación tecnológica, la dificultad para escalar proyectos de analítica y la falta de trazabilidad de los datos.
Sin embargo, trabajar con Databricks no es simplemente encender un cluster y cargar datos. Requiere entender su arquitectura, saber cuándo y cómo usar sus componentes, y aplicar buenas prácticas para maximizar su valor.
Conceptualización y arquitectura de Databricks
Databricks es una plataforma de análisis de datos en la nube que combina el poder de Apache Spark con un enfoque de Lakehouse Architecture, integrando capacidades de almacenamiento, procesamiento y analítica avanzada en un solo entorno. Está diseñada para soportar cargas de trabajo de ingeniería de datos, ciencia de datos, analítica de negocio y machine learning a gran escala.
Principios clave
- Unificación: combina Data Lake y Data Warehouse, permitiendo trabajar datos estructurados, semiestructurados y no estructurados en un único repositorio.
- Elasticidad: escala automáticamente recursos de cómputo para adaptarse a cargas variables.
- Colaboración: ofrece entornos interactivos (notebooks) para que ingenieros, científicos de datos y analistas trabajen sobre el mismo dataset en tiempo real.
Componentes principales de la arquitectura
- Workspace
– Capa de interacción del usuario donde se desarrollan notebooks, se administran repositorios de código y se configuran trabajos programados.
– Facilita la colaboración multiusuario con control de versiones y comentarios en línea.
– Integra Databricks Repos, Dashboards y Databricks SQL. - Clusters
– Unidad de cómputo basada en Spark para procesamiento distribuido.
Tipos:
- Interactive Clusters para exploración y análisis ad-hoc.
- Job Clusters creados/desechados automáticamente para ejecución de trabajos.
- Soporta Auto Scaling y GPU Clusters para cargas de deep learning.
- Delta Lake
– Capa transaccional que añade integridad y consistencia a datos sobre almacenamiento en la nube (S3, ADLS, GCS).
– Funciones clave: ACID Transactions, Time Travel, Z-Ordering y schema evolution.
– Facilita la transición de un Data Lake tradicional a un Lakehouse. - Unity Catalog
– Gobernanza centralizada para metadatos, permisos y auditoría.
– Control de acceso granular a nivel de tabla, columna y fila.
– Compatible con entornos multicloud y múltiples workspaces. - Job Scheduler y Orquestación
– Automatiza pipelines ETL/ELT, cargas incrementales y workflows de machine learning.
– Integración con Apache Airflow, Azure Data Factory, AWS Step Functions.
– Soporta ejecución programada o activada por eventos.
La fortaleza de Databricks no está solo en tener cada uno de estos componentes, sino en que están integrados en un flujo único que minimiza la fricción entre equipos y etapas del ciclo de vida del dato. Esto permite que desde la ingesta hasta la puesta en producción de un modelo de IA, todo ocurra en el mismo entorno con trazabilidad completa.
Arquitectura moderna de datos en la nube con Azure y Databricks
En el panorama actual de la analítica empresarial, las organizaciones necesitan infraestructuras que integren de forma ágil almacenamiento, procesamiento y analítica avanzada. La combinación de Azure y Databricks (imagen 1) se ha consolidado como una de las soluciones más potentes para cubrir este reto. Azure, como plataforma de nube híbrida y escalable, aporta el ecosistema de servicios necesarios para la gestión segura y eficiente de datos, mientras que Databricks, basado en Apache Spark y con un enfoque Lakehouse, unifica el procesamiento de datos por lotes y en tiempo real, la ciencia de datos y el machine learning en un solo entorno colaborativo.
Esta sinergia permite a las empresas romper los silos de información, optimizar costos operativos y acelerar el time-to-insight. Desde la ingesta de datos masivos, su transformación y almacenamiento optimizado, hasta la visualización interactiva y el despliegue de modelos predictivos, Azure y Databricks ofrecen un flujo de trabajo integrado que facilita la innovación y la toma de decisiones estratégicas. Además, al incorporar herramientas de gobernanza, seguridad y orquestación nativas de Azure, se garantiza que la analítica no solo sea potente, sino también confiable, escalable y alineada con las políticas corporativas.
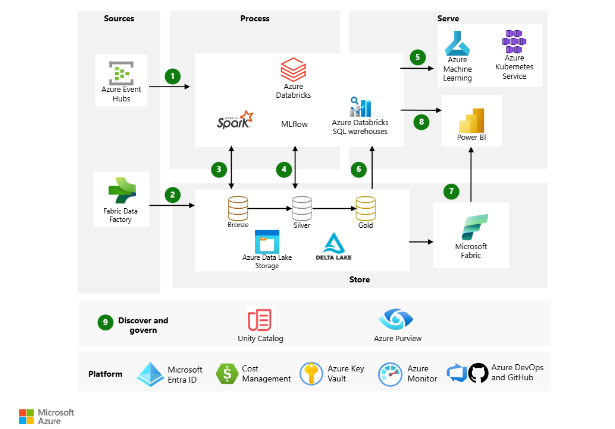
Imagen 1. Solución de Azure y Databricks.
Recuperada de:https://learn.microsoft.com/en-us/azure/architecture/solution-ideas/articles/azure-databricks-modern-analytics-architecture?utm_source
Flujo de datos:
- Azure Databricks ingiere datos de transmisión sin procesar desde Azure Event Hubs mediante Delta Live Tables.
2. Fabric Data Factory carga datos de lotes sin procesar en Data Lake Storage.
3. Para el almacenamiento de datos:
- Data Lake Storage alberga todo tipo de datos, incluyendo datos estructurados, no estructurados y parcialmente estructurados. También almacena datos por lotes y en streaming.
- Delta Lake constituye la capa depurada del lago de datos. Almacena los datos refinados en un formato de código abierto.
- Azure Databricks funciona bien con una arquitectura de medallón que organiza los datos en capas:
- Capa de bronce: contiene datos sin procesar.
- Capa de plata: contiene datos limpios y filtrados.
- Capa dorada: almacena datos agregados que son útiles para el análisis empresarial.
- La plataforma analítica ingiere datos de distintas fuentes de lotes y streaming. Los científicos de datos utilizan estos datos para tareas como:
- Preparación de datos.
- Exploración de datos.
- Preparación del modelo.
- Entrenamiento de modelos.
MLflow gestiona el seguimiento de parámetros, métricas y modelos en ejecuciones de código de ciencia de datos. Las posibilidades de codificación son flexibles:
- El código puede estar en SQL, Python, R y Scala.
- El código puede utilizar bibliotecas y marcos de código abierto populares como Koalas, Pandas y scikit-learn, que están preinstalados y optimizados.
- Los usuarios pueden optimizar el rendimiento y el costo mediante el uso de opciones de cómputo de un solo nodo o de múltiples nodos.tiles para el análisis empresarial.
- Los modelos de aprendizaje automático están disponibles en los siguientes formatos:
- Azure Databricks almacena información sobre los modelos en el Registro de Modelos de MLflow . Este registro facilita el acceso a los modelos mediante API por lotes, streaming y REST.
- La solución también puede implementar modelos en servicios web de Azure Machine Learning o Azure Kubernetes Service (AKS).
- Los servicios que trabajan con los datos se conectan a una única fuente de datos subyacente para garantizar la coherencia. Por ejemplo, se pueden ejecutar consultas SQL en el lago de datos mediante almacenes de SQL de Azure Databricks. Este servicio:
- Proporciona un editor y catálogo de consultas, historial de consultas, panel de control básico y alertas.
- Utiliza seguridad integrada que incluye permisos a nivel de fila y permisos a nivel de columna.
- Utiliza un motor Delta impulsado por Photon para mejorar el rendimiento.
- Puede replicar conjuntos de datos de referencia del catálogo de Unity de Azure Databricks en Fabric. Use la replicación de Azure Databricks en Fabric para una integración sencilla sin necesidad de mover ni replicar datos.
- Power BI genera informes y paneles analíticos e históricos desde la plataforma de datos unificada. Este servicio utiliza las siguientes características cuando funciona con Azure Databricks:
- Un conector de Azure Databricks integrado para visualizar los datos subyacentes.
- Controladores de conectividad de base de datos Java optimizados y conectividad de base de datos abierta.
- Puede usar Direct Lake con la duplicación de Azure Databricks en Fabric para cargar sus modelos semánticos de Power BI para consultas de mayor rendimiento.
- Power BI genera informes y paneles analíticos e históricos desde la plataforma de datos unificada. Este servicio utiliza las siguientes características cuando funciona con Azure Databricks:
- Un conector de Azure Databricks integrado para visualizar los datos subyacentes.
- Controladores de conectividad de base de datos Java optimizados y conectividad de base de datos abierta.
- Puede usar Direct Lake con la duplicación de Azure Databricks en Fabric para cargar sus modelos semánticos de Power BI para consultas de mayor rendimiento.
- La solución utiliza Unity Catalog y servicios de Azure para colaboración, rendimiento, confiabilidad, gobernanza y seguridad:
- El catálogo de Unity de Azure Databricks proporciona control de acceso centralizado, auditoría, linaje y capacidades de descubrimiento de datos en todos los espacios de trabajo de Azure Databricks
- Microsoft Purview proporciona servicios de descubrimiento de datos, clasificación de datos confidenciales y conocimientos de gobernanza en todo el patrimonio de datos.
- Azure DevOps ofrece integración continua e implementación continua (CI/CD) y otras funciones de control de versiones integradas.
- Azure Key Vault le ayuda a administrar de forma segura secretos, claves y certificados.
- Microsoft Entra ID y el aprovisionamiento del Sistema para la Administración de Identidades entre Dominios (SCIM) proporcionan inicio de sesión único para usuarios y grupos de Azure Databricks. Azure Databricks admite el aprovisionamiento automatizado de usuarios con Microsoft Entra ID para:
- Crear nuevos usuarios y grupos.
- Asignar a cada usuario un nivel de acceso.
- Eliminar usuarios y negarles el acceso.
- Azure Monitor recopila y analiza la telemetría de los recursos de Azure. Al identificar problemas de forma proactiva, este servicio maximiza el rendimiento y la confiabilidad.
- Microsoft Cost Management proporciona servicios de gobernanza financiera para cargas de trabajo de Azure.
¿Cuáles son los errores más comunes?
En la implementación de una arquitectura moderna con Azure y Databricks es frecuente encontrar errores que comprometen la calidad y eficiencia de la solución. Uno de los más comunes es no separar correctamente las capas bronce, plata y oro, lo que dificulta el linaje y la trazabilidad de los datos. A esto se suma la ausencia de una estrategia de gobernanza y control de permisos desde el inicio, así como la ingesta de información sin estandarizar formatos o esquemas. En la capa de almacenamiento, un particionamiento ineficiente en Delta Lake y la falta de control sobre clusters, ya sea por sobredimensionamiento o uso prolongado sin necesidad pueden incrementar costos y afectar el rendimiento. También es habitual que la orquestación de procesos esté dispersa entre diferentes servicios sin una documentación central, que no se gestione el linaje ni el versionado de datos, y que se realicen cargas con duplicados. Finalmente, la ausencia de monitoreo proactivo y la falta de capacitación del equipo en buenas prácticas de Lakehouse pueden limitar la escalabilidad y el aprovechamiento pleno de la plataforma.
¿Cuáles son las ventajas más representativas?
En una arquitectura moderna de datos, la combinación de Azure y Databricks ofrece ventajas significativas que impactan tanto en el rendimiento como en la gobernanza y la escalabilidad. En primer lugar, la unificación del procesamiento por lotes y en tiempo real permite que datos de distintas fuentes, ya sean históricos o en streaming, se integren de forma fluida en un mismo entorno. Gracias a Delta Lake, se obtiene almacenamiento transaccional con control de versiones, lo que asegura integridad, trazabilidad y calidad de datos. Además, el uso de clusters elásticos en Databricks permite optimizar recursos y costos, adaptándose dinámicamente a las cargas de trabajo.
En el plano de la analítica, esta integración habilita procesos avanzados de machine learning con MLflow y despliegues rápidos en Azure Machine Learning o Kubernetes, mientras que herramientas como Power BI y Microsoft Fabric facilitan la visualización interactiva con acceso directo a datos actualizados. La gobernanza centralizada con Unity Catalog y Microsoft Purview garantiza cumplimiento normativo, control de accesos granular y descubrimiento de datos en todo el ecosistema. Finalmente, el soporte nativo para múltiples lenguajes, librerías open source y servicios de Azure convierte esta arquitectura en una plataforma flexible, escalable y lista para innovación continua.
Si este artículo despertó tu interés y quieres profundizar en cómo Databricks puede transformar la arquitectura de datos de tu organización, en Quind contamos con la experiencia y el conocimiento para guiarte en cada etapa de la implementación. Desde el diseño inicial hasta la optimización de pipelines y la gobernanza de datos, nuestro equipo puede ayudarte a aprovechar todo el potencial de esta plataforma.
Conclusiones
La integración de Azure y Databricks ofrece un marco sólido y escalable para gestionar datos de forma unificada, optimizando tanto el procesamiento por lotes como en tiempo real. La arquitectura Lakehouse, respaldada por Delta Lake y complementada con herramientas como Unity Catalog y Microsoft Purview, asegura calidad, trazabilidad y gobernanza en todo el ciclo de vida del dato.
Su capacidad para adaptarse a distintos volúmenes y formatos, junto con la flexibilidad de soportar múltiples lenguajes y bibliotecas open source, la convierte en una solución versátil para empresas que buscan acelerar su analítica y potenciar el desarrollo de modelos de machine learning.
Adoptar esta arquitectura no solo implica mejoras técnicas, sino también beneficios estratégicos: reducción de costos operativos, mayor velocidad de obtención de insights y una base sólida para la innovación continua. Con la experiencia adecuada, organizaciones de cualquier sector pueden transformar sus datos en un activo clave para la toma de decisiones.
Bibliografía
- Databricks. (2024). Databricks Documentation. Recuperado de https://docs.databricks.com
- Microsoft. (2024). Creación de una arquitectura de análisis moderno mediante Azure Databricks. Microsoft Learn. Recuperado de https://learn.microsoft.com/es-es/azure/architecture/solution-ideas/articles/azure-databricks-modern-analytics-architecture
- Microsoft. (2024). Unity Catalog: Centralized Governance for Databricks Workspaces. Microsoft Learn. Recuperado de https://learn.microsoft.com/en-us/azure/databricks/data-governance/unity-catalog
- Delta Lake: The Key to Taking Data Management to the Next Level. Recuperado de: https://quind.io/blog/analitica/delta-lake-the-key-to-taking-data-management-to-the-next-level/
- La Arquitectura de Datos en la Era de la Información. Recuperado de: https://quind.io/blog/analitica/la-arquitectura-de-datos-en-la-era-de-la-informacion/