


Observabilidad: Ojos en tiempo real sobre el sistema
Luis Armando Rodriguez
Uno de los principales retos que enfrentamos los equipos que trabajamos con sistemas distribuidos en la nube, es la capacidad de comprender cómo se ejecutan las diferentes tareas de nuestras aplicaciones y el estado general de las mismas, para determinar si el proceso tiene problemas de desempeño o cuellos de botella, e identificar los componentes que han fallado. Estos retos se pueden superar mediante sistemas que habiliten la observabilidad de una manera estructurada como se evidencia en la siguiente imagen:
 Figura 1. Telemetría recolectada por un sistema de observabilidad.
Figura 1. Telemetría recolectada por un sistema de observabilidad.
Ahora, para comprender un poco la observabilidad tenemos que comprender la filosofía de trabajo, la cual se enfoca en informar los problemas que están sucediendo e identificar porqué están ocurriendo, para ello se hace uso de la telemetría que se puede captar por medio de las diferentes salidas del sistema: trazas (traces), logs y métricas (metrics); gracias a esta información recolectada se definen los 3 pilares fundamentales que nos permiten caracterizar a nuestro sistema como observable, los cuales son:
1. Logging : Observa el detalle de cada evento en tu sistema.
El logging es una práctica que permite gestionar, manejar y administrar los logs que imprime nuestro sistema con el propósito de brindar al personal encargado la información necesaria sobre lo que sucede en nuestras aplicaciones y/o sistemas. Dado que los logs son elementos configurados por el equipo de desarrollo, es necesario tener buenas prácticas en su construcción con el fin de optimizar su lectura y el consumo de disco para su almacenamiento, estas sugerencias se describirán en un próximo artículo.
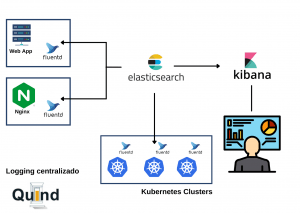 Figura 2. Logging centralizado.
Figura 2. Logging centralizado.
Esta práctica busca centralizar la telemetría de nuestro ambiente de trabajo con el fin de facilitar su extracción y consulta, cuando tengamos la necesidad de revisar los eventos en un componente puntual de nuestro sistema facilitando el análisis de los eventos en nuestro sistema con el fin de plantear continuamente posibles mejoras, reduciendo así el tiempo en la toma de decisiones.
2. Tracing : Seguimiento end-to-end a las peticiones de nuestros clientes.
Mientras que el logging nos brinda información sobre un evento puntual en una aplicación o elemento de nuestro sistema, el tracing nos ofrece una descripción más general de este. En este pilar se gestionan y administran trazas (seguimiento a una transacción o solicitud individual de un cliente en nuestra aplicación a través de sus capas) de extremo a extremo (end-to-end) abordando así las diferentes capas e interacciones de los componentes técnicos que hacen parte de nuestra aplicación. De esta forma una traza nos muestra los sistemas que interactúan para completar una transacción de negocio y también los tiempos de respuesta.
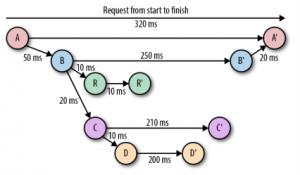 Figura 3. Gráfico de acíclico de una petición.
Figura 3. Gráfico de acíclico de una petición.
La figura 3 es una representación gráfica de la información que nos brinda una traza. Esta información centralizada nos permite comparar los tiempos de procesamiento de las solicitudes entre nuestras apps, así como generar indicadores de las respuestas a los clientes.
3. Monitoreo : Visualización del estado de recursos
Por último, pero no menos importante tenemos el pilar de monitoreo donde se gestionan, manejan y administran las métricas (representación numérica del consumo o medida estado de un recurso) recopiladas de nuestro sistema. De esta forma tenemos la capacidad de observar el desempeño de nuestras aplicaciones y relacionarlo con la calidad de nuestros servicios.
La gran mayoría de herramientas que habilitan este pilar, nos permiten generar alarmas y ejecutar acciones de forma automatizada sobre nuestros ambientes con base a comportamientos no deseados. Cuando se notifica una alarma, los administradores de la plataforma se pueden apoyar en los logs y trazas para identificar la causa raíz.
Dados los diferentes tipos de datos que se recopilan en un sistema de observabilidad es recomendable que la centralización, manejo y visualización de la información sea mediante una sola herramienta. En Quind trabajamos con la filosofía de integrar herramientas robustas y estables en el tiempo privilegiando la adopción de tecnologías Open Source, entre ellas: Fluentd, Opentelemetry, Jaeger, Prometheus entre otras. Estamos comprometidos en la adopción de herramientas que posean un impacto mínimo de trabajo en su implementación, con baja inversión en infraestructura y a su vez sean escalables y mantenibles en el tiempo.
¿Cuáles son los beneficios que nos brinda la observabilidad?
En un ambiente productivo, donde se hayan implementado procesos de logging, tracing y monitoreo, tendremos como resultado un sistema observable mucho más fácil de comprender y controlar. La habilidad de poder analizar qué elementos tienen cierta recurrencia a fallar o ralentizando los procesos nos permite realizar refinamientos u optimizaciones a nivel de desarrollo mucho más estructurados y efectivos.
Esta visibilidad en cuanto a problemas reduce el estrés al efectuar cambios con el fin de expandir el negocio, basados en la seguridad que nos brindan estas herramientas al visualizar en tiempo real el comportamiento de nuestro sistema, podemos tener la confianza de saber si estamos obteniendo los resultados deseados o si por el contrario tenemos que revertir dichos procesos.
En la actualidad las herramientas de observabilidad son indispensables en equipos de trabajo con un alto grado de innovación en sus procesos, estas le brindan mediante vistas compartidas la capacidad de trabajar en una sola dirección y garantiza la comunicación entre estos.